Hola a todos, me estreno con este tutorial sobre robots.txt, espero que les sea de su agrado 
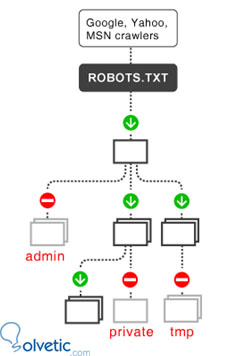
Los robots son de uso frecuente por los motores de búsqueda para categorizar archivos de los sitios Webs, o por los webmasters para corregir o filtrar el código fuente. El archivo robots.txt, tiene ciertas directivas que se deben cumplir.
Vamos a analizar y especificar distintos código fuente de un robots.txt:
Permitir que todos los robots visiten todos los archivos que se encuentran almacenados en el directorio raíz de la web:
Impedir acceso a todos los robots y todos los archivos almacenados en el directorio raíz:
Permitir que solo un robots acceda, en este ejemplo solo Google podra rastrear
Los robots mas conocidos tiene el un nombre para utilizar en user-agent
googlebot => para Google
msnbot => MSN Search
yahoo-slurp => Yahoo
scrubby => Scrub The Web
robozilla => DMOZ Checker
ia_archiver => Alexa/Wayback
baiduspider => Baidu
También están los robots mas específicos como los de imágenes
googlebot-image => Google Image
googlebot-mobile => Google Mobile
Otro ejemplo para que todos los subdirectorios que incluyan el comodín (/) deben ser bloqueados, únicamente éstos, exceptuando a todos los demás archivos y directorios que no contienen un comodín, nomrmal mente se bloquean los directorios de sistema o back end:
Impedir que un archivo concreto sea rastreado
Esto se utiliza mucho cuando queremos eliminar una pagina que da error 404 o para eliminar una pagina de los resultados de busqueda, asi evitamos que sea rastreada.
Gestionar la frecuencia de rastreo de los robots
Desde Google analytics y desde webmastertools se puede ver las estadísticas también puedes observar que a veces algunos robots se toman mucho tiempo revisando nuestro sitio y someten a peticiones al servidor, los robots consumen ancho de banda y recursos como si fueran un visitantes mas.
Existe un modo de que no se descontrolen los robots, podemos decirle a cada uno
User-agent: googlebot Crawl-delay: 30
Con esto le informamos al robot de Google que espere 30 segundos entre cada rastreo. Cuidado, porque Crawl-delay puede que no lo soportan todos los buscadores, Bing y Google si lo soportan.
La web oficial de robots.txt es http://www.robotstxt.org/ donde encontraremos los nombre de todos los robots, especificaciones sobre el codigo. Aqui se expone que los robots sirven para estandarizar los que deben rastrear y son utilizados en otras plataformas para rastrear y validar html, validar enlaces, indexar informacion, actualizar contenido en buscadores, proteger sitios web.
Los robots son de uso frecuente por los motores de búsqueda para categorizar archivos de los sitios Webs, o por los webmasters para corregir o filtrar el código fuente. El archivo robots.txt, tiene ciertas directivas que se deben cumplir.
Vamos a analizar y especificar distintos código fuente de un robots.txt:
Permitir que todos los robots visiten todos los archivos que se encuentran almacenados en el directorio raíz de la web:
User-agent: * Disallow:
Impedir acceso a todos los robots y todos los archivos almacenados en el directorio raíz:
User-agent: * Disallow: /
Permitir que solo un robots acceda, en este ejemplo solo Google podra rastrear
User-agent: googlebot Disallow: User-agent: * Disallow: /
Los robots mas conocidos tiene el un nombre para utilizar en user-agent
googlebot => para Google
msnbot => MSN Search
yahoo-slurp => Yahoo
scrubby => Scrub The Web
robozilla => DMOZ Checker
ia_archiver => Alexa/Wayback
baiduspider => Baidu
También están los robots mas específicos como los de imágenes
googlebot-image => Google Image
googlebot-mobile => Google Mobile
Otro ejemplo para que todos los subdirectorios que incluyan el comodín (/) deben ser bloqueados, únicamente éstos, exceptuando a todos los demás archivos y directorios que no contienen un comodín, nomrmal mente se bloquean los directorios de sistema o back end:
User-agent: * Disallow: /cgi-bin/ Disallow: /images/ Disallow: /tmp/ Disallow: /adminstrador/
Impedir que un archivo concreto sea rastreado
User-agent: * Disallow: /pagina.htm
Esto se utiliza mucho cuando queremos eliminar una pagina que da error 404 o para eliminar una pagina de los resultados de busqueda, asi evitamos que sea rastreada.
Gestionar la frecuencia de rastreo de los robots
Desde Google analytics y desde webmastertools se puede ver las estadísticas también puedes observar que a veces algunos robots se toman mucho tiempo revisando nuestro sitio y someten a peticiones al servidor, los robots consumen ancho de banda y recursos como si fueran un visitantes mas.
Existe un modo de que no se descontrolen los robots, podemos decirle a cada uno
User-agent: googlebot Crawl-delay: 30
Con esto le informamos al robot de Google que espere 30 segundos entre cada rastreo. Cuidado, porque Crawl-delay puede que no lo soportan todos los buscadores, Bing y Google si lo soportan.
La web oficial de robots.txt es http://www.robotstxt.org/ donde encontraremos los nombre de todos los robots, especificaciones sobre el codigo. Aqui se expone que los robots sirven para estandarizar los que deben rastrear y son utilizados en otras plataformas para rastrear y validar html, validar enlaces, indexar informacion, actualizar contenido en buscadores, proteger sitios web.


