Los cambios en Git no son iguales que en otros sistemas de manejo y control de versiones, ya que por la característica de almacenar solo lo que realmente ha cambiado, hace que se disminuya el tamaño de los archivos generados para el control y también se le da una agilidad mayor.
El aspecto que controla todo esto es el index quien tiene la responsabilidad de saber quién, que y cuando de todos los cambios realizados, es por ello que luego de agregar los diferentes aspectos a nuestro index de branch se hace el llamado commit.
El manejo de recursos que hace que esto sea tan rápido se debe a que se hacen comparaciones a través de SHA1 por lo que si los elementos dentro del index tienen un mismo hash no se siguen ahondando en sus cambios ya que son idénticos y así solo se va tomando los archivos que realmente cambiaron.
La forma en que se organizan los commits nos permite establecer estructuras jerárquicas que dan la certeza de conseguir el origen de todos los cambios registrados, así si seguimos las mejores prácticas de Git nunca estaremos perdidos, gracias a los identificadores únicos también podremos estar seguros que si alguna funcionalidad ha creado un problema esta puede ser encontrada en el punto exacto en que se incluyó.
Comentábamos como los commits tienen un hash en SHA1 con lo cual pueden ser identificados, resulta que este hash también los hace únicos e irrepetibles, es decir, si tenemos un commit y en otro repositorio se encuentra el mismo hash entonces podemos saber que es el mismo commit.
Debido a esto el commit es también considerado atómico, es decir, como una sola unidad independientemente que almacene el estado de muchos directorios o archivos, con esto podemos referirnos al commit como una unidad dentro de nuestro repositorio y así poder tratar cada uno como un elemento que aunque tiene relación con el anterior es único.
A pesar que el hash SHA1 nos sirve como identificador único para el commit, su estructura de 40 caracteres alfanuméricos puede representar un problema cuando queremos comunicarnos con otro desarrollador y explicarle de que commit estamos hablando.
Para hablar del último commit del branch simplemente podemos referirnos a HEAD, ya que este siempre va a hacer referencia al último y más reciente commit, sin embargo como no siempre vamos a requerir esto, basta con que utilicemos los primeros caracteres del hash, aunque no siempre va ser único, por ello con añadir más caracteres lograremos la unicidad correspondiente.
Veamos entonces el comando que debemos utilizar para lograr esto último:
Ahora veremos en la siguiente imagen como identificamos un commit dentro de nuestro repositorio de pruebas, para ello vamos a ubicar inicialmente cual es el SHA1 del HEAD y luego vamos a llamarlo por sus primeros caracteres, veamos:
Con el ejemplo anterior hemos descubierto una herramienta de Git que nos puede ser mucha utilidad y es el comando log, este es muy poderoso ya que nos permite ubicar los diferentes commit de una manera rápida y precisa, sin embargo tiene muchos parámetros y configuraciones que pueden ser difíciles de memorizar en primera instancia, sin embargo para utilizarlo no necesitamos aprenderlas todas, podemos ir poco a poco mientras vamos acostumbrándonos a su uso.
Si queremos ver la historia de commits, basta con hacer lo siguiente:
Con ello obtendremos la información detallada de la historia de nuestro branch y sus commits, veamos como luce en nuestra consola en el repositorio de pruebas que tenemos:
Notamos entonces como los commits son organizados desde el más reciente hasta el más antiguo, esto nos permite ver un poco la línea histórica de los cambios sufridos por el branch elegido para ver el log histórico.
Como trabajar en consola a veces es un poco pesado, aunque es muy necesario, Git nos ofrece una herramienta que nos permite hacer la revisión del historial de commits de forma gráfica y es gitk no es un subcomando de Git como por ejemplo log que ya vimos, sino que es un comando independiente y nos permite acceder a un detalle mayor del branch y su historial.
Para utilizarlo simplemente debemos ejecutar el siguiente comando:
Veamos cómo se ve en la consola la ejecución del mismo:
Aunque pueda parecer que nada pasó, en breve obtendremos una ventana con el gráfico solicitado para el branch especificado como podemos ver en la siguiente captura de pantalla:
![commits-en-git4.jpg]()
Podemos notar que tenemos un detalle mucho mayor, además de la mejora en visualización del mismo.
Refs y Symrefs corresponden a referencias y referencias simbólicas respectivamente, la primera corresponde a un identificador SHA1 de un objeto dentro del marco de objetos de nuestro repositorio, en cambio la segunda corresponde de forma indirecta a un objeto, a pesar de su nombre también es una referencia.
Esta estructura de referencias es muy importante conocerlas ya que nos va permitir entender la organización de nuestro directorio de commits y branches dentro de Git, las cuales están almacenadas en el directorio .git/ref.
Por último veamos como luce la ejecución de este comando cuando la aplicamos sobre nuestro repositorio de pruebas:
Otro aspecto interesante de los commits, es que podemos trabajar con los nombres relativos, esto hace que encontrar rangos de commits sea muy sencillo, por ejemplo si queremos localizar lo que existe entre las revisiones de un periodo determinado podemos hacerlo.
Para lograr esto solamente debemos utilizar el nombre del branch mas el símbolo ^ y el número de la revisión. Por ejemplo master^ donde nos referimos al penúltimo cambio hecho en el branch master.
Un ejemplo puede ser master^2~3 para referirnos a cambios históricos dentro de nuestro repositorio, si queremos obtener el nombre de un commit relativo simplemente debemos utilizar el siguiente comando:
Esto nos devolverá el SHA1 del commit al cual llegamos. Veamos en la siguiente imagen como podemos obtener el nombre del commit actual de master y con master~ el nombre del primer padre del mismo que sería el commit del cual partimos:
Notamos entonces como pudimos obtener dos SHA1 diferentes y validos dentro de nuestro repositorio, únicamente utilizando nombres relativos.
Con esto finalizamos este tutorial, hemos introducido nuevos conceptos de lo que representan los commits dentro de Git, esto nos da la posibilidad de entender de mejor forma la estructuras de nuestros repositorios, con ello la organización nos parecerá más lógica y así podremos ser mucho más efectivos al manejar los cambios dentro de nuestro código. La forma en la que Git administra las diferencias lo hace tan especial y es por ello que se ha convertido en uno de los manejadores de versiones líderes de la actualidad tecnológica.
El aspecto que controla todo esto es el index quien tiene la responsabilidad de saber quién, que y cuando de todos los cambios realizados, es por ello que luego de agregar los diferentes aspectos a nuestro index de branch se hace el llamado commit.
¿Qué es un commit?
En Git sabemos que para poder añadir un cambio debemos hacer un commit del mismo una vez que ha sido añadido al index del repositorio. Sin embargo ¿Qué es un commit exactamente? Esta pregunta no siempre nos la hacemos ya que la forma en que Git maneja esto es bastante clara, pero un commit es la forma en la que Git registra el estado actual del index del repositorio y lo almacena en el objeto correspondiente, de esta forma cada commit va derivando del anterior y así se puede reutilizar la estructura que no sufre cambios.
El manejo de recursos que hace que esto sea tan rápido se debe a que se hacen comparaciones a través de SHA1 por lo que si los elementos dentro del index tienen un mismo hash no se siguen ahondando en sus cambios ya que son idénticos y así solo se va tomando los archivos que realmente cambiaron.
La forma en que se organizan los commits nos permite establecer estructuras jerárquicas que dan la certeza de conseguir el origen de todos los cambios registrados, así si seguimos las mejores prácticas de Git nunca estaremos perdidos, gracias a los identificadores únicos también podremos estar seguros que si alguna funcionalidad ha creado un problema esta puede ser encontrada en el punto exacto en que se incluyó.
El commit único e irrepetible
Comentábamos como los commits tienen un hash en SHA1 con lo cual pueden ser identificados, resulta que este hash también los hace únicos e irrepetibles, es decir, si tenemos un commit y en otro repositorio se encuentra el mismo hash entonces podemos saber que es el mismo commit.
Debido a esto el commit es también considerado atómico, es decir, como una sola unidad independientemente que almacene el estado de muchos directorios o archivos, con esto podemos referirnos al commit como una unidad dentro de nuestro repositorio y así poder tratar cada uno como un elemento que aunque tiene relación con el anterior es único.
Colocando el nombre al commit
A pesar que el hash SHA1 nos sirve como identificador único para el commit, su estructura de 40 caracteres alfanuméricos puede representar un problema cuando queremos comunicarnos con otro desarrollador y explicarle de que commit estamos hablando.
Nombres relativos
Para solventar este problema podemos establecer nombres relativos y más fáciles de recordar para los commits, estos no sustituyen al hash, si no que funcionan como una especie de etiqueta que nos permite identificarlos de forma más humana.
Para hablar del último commit del branch simplemente podemos referirnos a HEAD, ya que este siempre va a hacer referencia al último y más reciente commit, sin embargo como no siempre vamos a requerir esto, basta con que utilicemos los primeros caracteres del hash, aunque no siempre va ser único, por ello con añadir más caracteres lograremos la unicidad correspondiente.
Veamos entonces el comando que debemos utilizar para lograr esto último:
git log -1 --pretty=oneline identificadorcommit
Ahora veremos en la siguiente imagen como identificamos un commit dentro de nuestro repositorio de pruebas, para ello vamos a ubicar inicialmente cual es el SHA1 del HEAD y luego vamos a llamarlo por sus primeros caracteres, veamos:
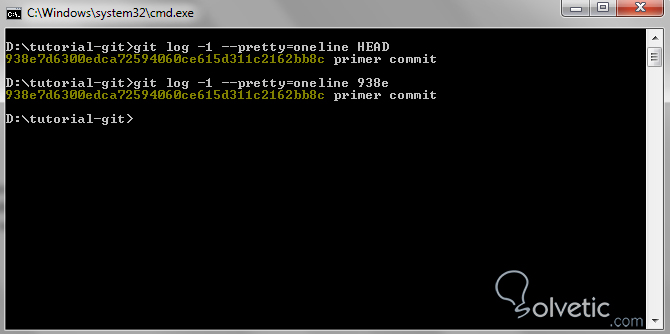
Git log, nuestro aliado explorador
Con el ejemplo anterior hemos descubierto una herramienta de Git que nos puede ser mucha utilidad y es el comando log, este es muy poderoso ya que nos permite ubicar los diferentes commit de una manera rápida y precisa, sin embargo tiene muchos parámetros y configuraciones que pueden ser difíciles de memorizar en primera instancia, sin embargo para utilizarlo no necesitamos aprenderlas todas, podemos ir poco a poco mientras vamos acostumbrándonos a su uso.
Si queremos ver la historia de commits, basta con hacer lo siguiente:
git log nombreBranch
Con ello obtendremos la información detallada de la historia de nuestro branch y sus commits, veamos como luce en nuestra consola en el repositorio de pruebas que tenemos:
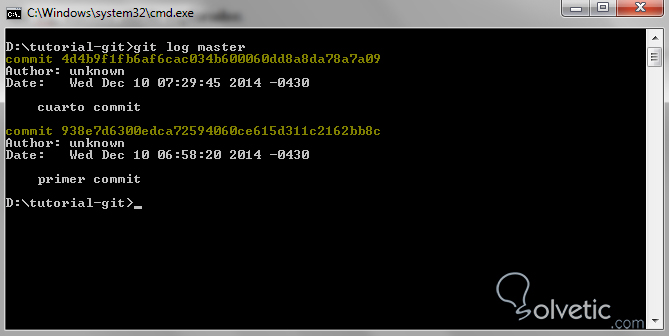
Notamos entonces como los commits son organizados desde el más reciente hasta el más antiguo, esto nos permite ver un poco la línea histórica de los cambios sufridos por el branch elegido para ver el log histórico.
Graficar los cambios
Como trabajar en consola a veces es un poco pesado, aunque es muy necesario, Git nos ofrece una herramienta que nos permite hacer la revisión del historial de commits de forma gráfica y es gitk no es un subcomando de Git como por ejemplo log que ya vimos, sino que es un comando independiente y nos permite acceder a un detalle mayor del branch y su historial.
Para utilizarlo simplemente debemos ejecutar el siguiente comando:
gitk nombreBranch
Veamos cómo se ve en la consola la ejecución del mismo:
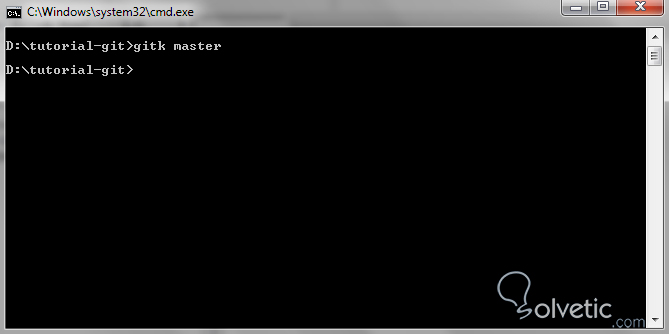
Aunque pueda parecer que nada pasó, en breve obtendremos una ventana con el gráfico solicitado para el branch especificado como podemos ver en la siguiente captura de pantalla:
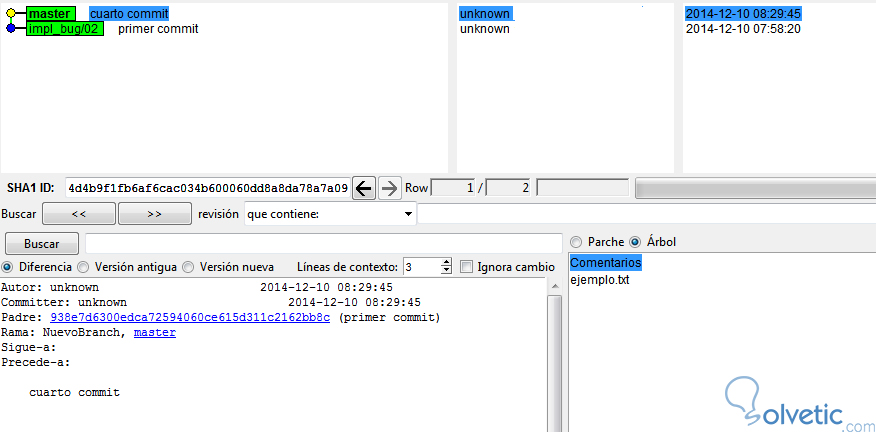
Podemos notar que tenemos un detalle mucho mayor, además de la mejora en visualización del mismo.
Refs y Symrefs
Refs y Symrefs corresponden a referencias y referencias simbólicas respectivamente, la primera corresponde a un identificador SHA1 de un objeto dentro del marco de objetos de nuestro repositorio, en cambio la segunda corresponde de forma indirecta a un objeto, a pesar de su nombre también es una referencia.
Esta estructura de referencias es muy importante conocerlas ya que nos va permitir entender la organización de nuestro directorio de commits y branches dentro de Git, las cuales están almacenadas en el directorio .git/ref.
Creando una referencia simbólica
Si queremos crear de forma explícita una referencia simbólica basta con utilizar el comando git symbolic-ref, y aunque es factible utilizar nombres como HEAD para estas referencias no es aconsejable ya que a final de cuentas pueden llevarnos a una confusión que puede ocasionar un daño en nuestro repositorio.
Por último veamos como luce la ejecución de este comando cuando la aplicamos sobre nuestro repositorio de pruebas:
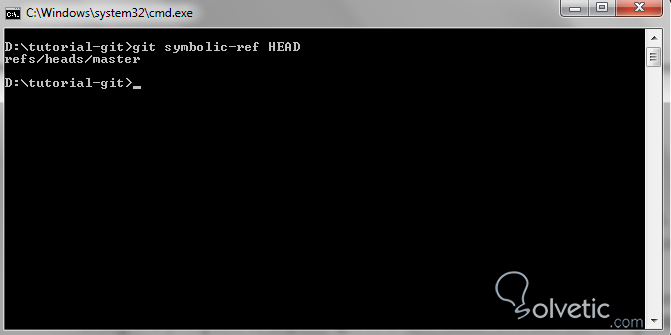
Nombres relativos en los commits
Otro aspecto interesante de los commits, es que podemos trabajar con los nombres relativos, esto hace que encontrar rangos de commits sea muy sencillo, por ejemplo si queremos localizar lo que existe entre las revisiones de un periodo determinado podemos hacerlo.
Para lograr esto solamente debemos utilizar el nombre del branch mas el símbolo ^ y el número de la revisión. Por ejemplo master^ donde nos referimos al penúltimo cambio hecho en el branch master.
Historial del repositorio
De esta forma podremos ir moviéndonos por todo el historial de nuestro repositorio, lo que nos da la posibilidad de acceder de forma relativa a los commits que han hecho posible que tengamos el actual, si seguimos la estructura master^2 nos va a llevar al segundo padre del commit, es decir, al que de forma paralela le ha dado vida, también con ~ podemos acceder al padre del padre de nuestro commit actual, es decir, el abuelo, por ponerlo de alguna forma en genealogía.
Un ejemplo puede ser master^2~3 para referirnos a cambios históricos dentro de nuestro repositorio, si queremos obtener el nombre de un commit relativo simplemente debemos utilizar el siguiente comando:
git rev-parse nombreRelativo
Esto nos devolverá el SHA1 del commit al cual llegamos. Veamos en la siguiente imagen como podemos obtener el nombre del commit actual de master y con master~ el nombre del primer padre del mismo que sería el commit del cual partimos:
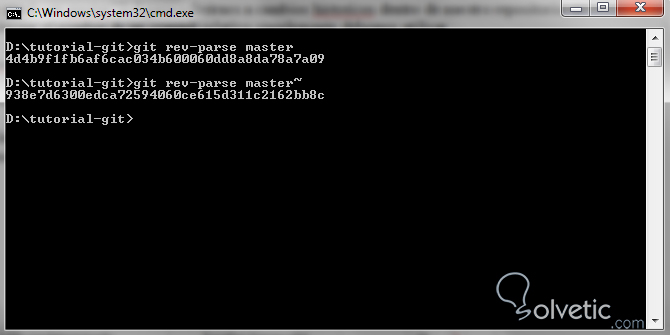
Notamos entonces como pudimos obtener dos SHA1 diferentes y validos dentro de nuestro repositorio, únicamente utilizando nombres relativos.
Con esto finalizamos este tutorial, hemos introducido nuevos conceptos de lo que representan los commits dentro de Git, esto nos da la posibilidad de entender de mejor forma la estructuras de nuestros repositorios, con ello la organización nos parecerá más lógica y así podremos ser mucho más efectivos al manejar los cambios dentro de nuestro código. La forma en la que Git administra las diferencias lo hace tan especial y es por ello que se ha convertido en uno de los manejadores de versiones líderes de la actualidad tecnológica.

