Imaginemos que tenemos una cantidad de documentos ya hechos que hemos decidido publicar en la web, lo ideal sería convertirlos en archivos descargables y se resolvería el caso, pero que hay si no queremos que sean descargables y que solo sean visibles en páginas web, entonces deberíamos crear documentos HTML para ello, sin embargo, generar a mano las etiquetas necesarias puede ser un dolor de cabeza.
Ante la situación planteada lo ideal es generar un programa que nos permita solventar dichas limitantes, para ello contamos con Python y gracias a sus diferentes herramientas para el procesamiento de texto podemos construir la solución que nos permitirá hacer esta tarea.
Condiciones
En orden de poder resolver un problema debemos primero establecer condiciones específicas que nos permitan saber que debemos realizar, para este proyecto en particular estableceremos las siguientes:
Herramientas a utilizar
Para lograr los objetivos planteados debemos definir que herramientas debemos utilizar, en este caso podemos tomar la librería estándar de entrada sys.stdin y para la salida nos será suficiente print, todo lo demás es trabajar con diferentes técnicas que veremos en los ejemplos.
Inicio
Ya que sabemos que necesitamos y hemos establecido nuestros objetivos, solo debemos tener una forma de cómo medir nuestro éxito y para ello es necesario que hagamos un documento con el cual podamos generar nuestras páginas, en el caso de este tutorial veremos un documento ejemplo en la siguiente imagen, sin embargo cualquier texto servirá siempre y cuando tenga varios párrafos:
Primera iteración
En la primera iteración necesitamos dividir los párrafos, en este caso los llamaremos bloques, sabemos que dichos bloques están separados por una o más líneas en blanco, entonces nuestro primer paso será tomar estas líneas como separadores.
El siguiente código lo que hará es recolectar las líneas que vaya encontrando hasta que encuentre una línea en blanco, entonces seguirá recorriendo el archivo hasta que encontremos otro grupo de texto.
Veamos como luce el código:
El código anterior lo guardaremos en un archivo llamado util.py, luego debemos incorporar las diferentes etiquetas en nuestro documento HTML resultante, para ello generaremos otro archivo con el siguiente código:
Como vemos utilizamos el método blocks() y le pasamos el archivo de entrada gracias a la librería sys.stdin. El archivo debe llamarse simple_markup.py y lo ejecutamos de la siguiente forma:
Cómo vemos le pasamos el archivo de texto inicial y le pasamos el nombre que debe contener la salida y debe lucir de la siguiente forma:
Terminando la primera iteración, finalizamos este tutorial, en la segunda parte del mismo seguiremos viendo más a profundidad estos conceptos, así como la segunda iteración para este programa.
Ante la situación planteada lo ideal es generar un programa que nos permita solventar dichas limitantes, para ello contamos con Python y gracias a sus diferentes herramientas para el procesamiento de texto podemos construir la solución que nos permitirá hacer esta tarea.
Condiciones
En orden de poder resolver un problema debemos primero establecer condiciones específicas que nos permitan saber que debemos realizar, para este proyecto en particular estableceremos las siguientes:
- El texto no debe requerir contener ningún tipo de código o etiquetas.
- Debe ser capaz de distinguir entre títulos, párrafos y listas, así como texto resaltado y URLs.
- Debe ser lo suficientemente robusto como para poder aplicarlo a otros lenguajes de marcado diferentes al HTML.
Herramientas a utilizar
Para lograr los objetivos planteados debemos definir que herramientas debemos utilizar, en este caso podemos tomar la librería estándar de entrada sys.stdin y para la salida nos será suficiente print, todo lo demás es trabajar con diferentes técnicas que veremos en los ejemplos.
Inicio
Ya que sabemos que necesitamos y hemos establecido nuestros objetivos, solo debemos tener una forma de cómo medir nuestro éxito y para ello es necesario que hagamos un documento con el cual podamos generar nuestras páginas, en el caso de este tutorial veremos un documento ejemplo en la siguiente imagen, sin embargo cualquier texto servirá siempre y cuando tenga varios párrafos:

Primera iteración
En la primera iteración necesitamos dividir los párrafos, en este caso los llamaremos bloques, sabemos que dichos bloques están separados por una o más líneas en blanco, entonces nuestro primer paso será tomar estas líneas como separadores.
El siguiente código lo que hará es recolectar las líneas que vaya encontrando hasta que encuentre una línea en blanco, entonces seguirá recorriendo el archivo hasta que encontremos otro grupo de texto.
Veamos como luce el código:
def lines(file): for line in file: yield line yield '\n' def blocks(file): block = [] for line in lines(file): if line.strip(): block.append(line) elif block: yield ''.join(block).strip() block = []
El código anterior lo guardaremos en un archivo llamado util.py, luego debemos incorporar las diferentes etiquetas en nuestro documento HTML resultante, para ello generaremos otro archivo con el siguiente código:
from __future__ import generators import sys, re from util import * print '<html><head><title>...</title><body>' title = 1 for block in blocks(sys.stdin): block = re.sub(r'\*(.+?)\*', r'<em>\1</em>', block) if title: print '<h1>' print block print '</h1>' title = 0 else: print '<p>' print block print '</p>' print '</body></html>'
Como vemos utilizamos el método blocks() y le pasamos el archivo de entrada gracias a la librería sys.stdin. El archivo debe llamarse simple_markup.py y lo ejecutamos de la siguiente forma:
$ python simple_markup.py < test_input.txt > test_output.html
Cómo vemos le pasamos el archivo de texto inicial y le pasamos el nombre que debe contener la salida y debe lucir de la siguiente forma:
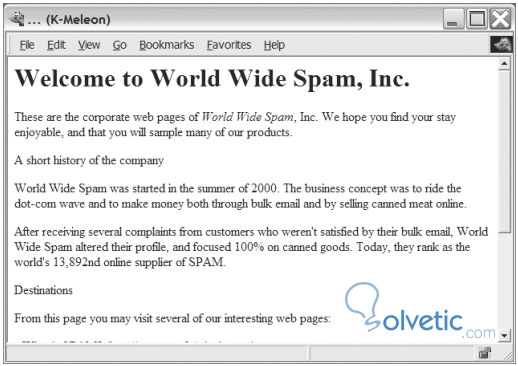
Terminando la primera iteración, finalizamos este tutorial, en la segunda parte del mismo seguiremos viendo más a profundidad estos conceptos, así como la segunda iteración para este programa.

