Python nos permite trabajar con archivos remotos, tal vez esto no suene lógico de esta manera, pero los archivos remotos en este caso no son más que consultas a páginas Web desde nuestro programa Python, la razón para hacer esto puede ser desde hacer consultas a Web Services REST que nos permitan obtener valores por GET o hacer consulta directamente a páginas y manipular su contenido.
Para lograr esto nos valdremos de algunas de las muchas librerías que ofrece Python para el trabajo con redes, quitando de esta forma los obstáculos técnicos y solamente concentrándonos en lo importante que es en nuestra lógica de programación.
Estas dos librerías urllib y urllib2 nos permiten hacer el trabajo de acceder a archivos a través de la red como si estuviesen en nuestro ambiente local, a través de una sencilla llamada a una función, esto nos puede servir para muchas cosas por ejemplo que podamos utilizar una Web y con su contenido hacer reportes en nuestro programa de lo que podamos encontrar en él mismo.
Estas dos librerías son similares, su diferencia radica en que urllib2 puede que sea un poco más sofisticada, donde si queremos simplemente hacer una consulta sin más implicaciones podemos utilizar urllib, pero si queremos hacer algún proceso de autenticación o utilizar cookies, entonces urllib2 puede que sea la opción correcta para nuestro programa.
Ya que sabemos teóricamente que necesitamos y para que lo necesitamos, veamos un pequeño ejemplo en código para que nos quede claro que podemos hacer, en el siguiente ejemplo vamos a abrir una Web desde nuestro programa y luego a través de expresiones regulares vamos a extraer un link de su contenido para ello vamos a utilizar urllib:
>>> from urllib import urlopen
>>> webpage = urlopen('http://www.python.org')
>>> import re
>>> text = webpage.read()
>>> m = re.search('<a href="([^"]+)">Tutorial</a>', text, re.IGNORECASE)
>>> m.group(1)
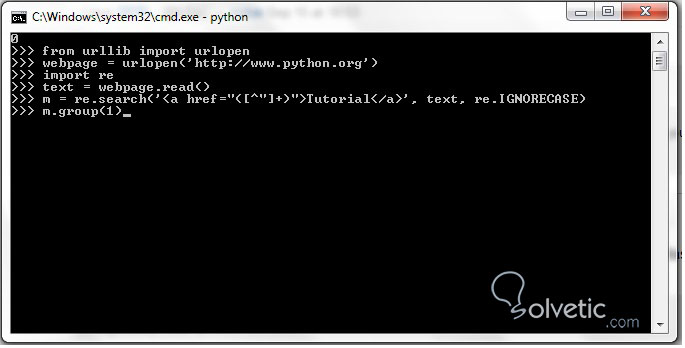
Vamos paso a paso, primero de la librería urllib importamos urlopen, luego creamos una variable llamada webpage que es la que va a contener el resultado de urlopen que le haremos a la página oficial de Python, ya con esto importamos re para poder trabajar con expresiones regulares, decimos que text es la variable que tendrá el contenido de la lectura de la página, hacemos una búsqueda con expresión regular y por último agrupamos el resultado lo que nos debería imprimir lo siguiente:
Esto es gracias al método urlopen, que lo que haces es que nos deja trabajar con la página Web como si fuese un objeto archivo, de esta forma podemos aplicar muchas de las funciones que podemos utilizar con este tipo de objetos, inclusive si queremos podemos descargar la página y trabajarla desde nuestro local de una forma muy fácil utilizando el método urlretrieve de la siguiente forma:
urlretrieve('http://www.python.org', 'C:\\python_webpage.html')Lo único que hacemos es pasar como segundo parámetro la ruta en nuestro ambiente local donde debería guardarse el archivo con la copia de la página sin muchas dificultades.
Con esto finalizamos este tutorial, como vemos hacer trabajos más complejos como utilizar páginas en nuestros programas es bastante sencillo gracias a las librerías de Python.

