Cuando hacemos múltiples queries en un sistema complejo muchas veces no tomamos la ruta adecuada para tener un óptimo rendimiento a nivel de bases de datos, con el avance tecnológico actual y la potencia de computo que muchas veces vemos en nuestros servidores podemos pensar que la optimización de bases de datos es un asunto del pasado.
Esto no puede estar más lejos de la realidad, a pesar del avance en potencia de los equipos, las bases de datos son fundamentales para el rendimiento de las aplicaciones, por esta razón un query bien escrito y altamente optimizado puede significar varios segundos de carga que se ahorra en el sistema, si esto lo multiplicamos por la cantidad de usuarios concurrentes vemos como el costo y la potencia se estaban desaprovechando.
Optimizar Queries
La mejor forma de mejorar el rendimiento de nuestras bases de datos es iniciar con queries bien escritos, muchas veces encontramos que los queries no están bien escritos ya que no están tan optimizados como deberían estarlo, existen muchas causas para esto, una de ellas es la reutilización sin conciencia de código; con esto nos referimos a que si en algún momento hicimos un query que nos funciona con un left join lo seguiremos aplicando al aumentar la cantidad de tablas a consultar, cuando al modificarlo y cambiar algunas cláusulas por inner join pudiera acortar el camino y ahorrar consumo de procesador.
SQL es un lenguaje que a pesar que es bastante sencillo de leer, tiene muchas vertientes y muchas variaciones que nos permiten hacer algo que funcione de la mejor y de la peor forma, está de parte nuestra saber identificar si nuestra solución pertenece a una categoría u otra.
Para poder saber que estamos por el buen camino una de las cosas más importantes es estar actualizados, es decir, no podemos continuar codificando en SQL dentro de PostgreSQL como si fuese la primera versión cuando estamos en la versión 9.
Sobre Utilización de Sub-consultas
Esta es una de los errores más comunes que cometemos, y es que pensamos en un query como un conjunto de piezas que vamos engranando hasta obtener un resultado final, sin embargo este comportamiento es de alto impacto para el rendimiento de nuestra base de datos.
Veamos un ejemplo de este típico comportamiento:
Ahora, si vemos el gráfico del EXPLAIN de este query nos daremos cuenta lo costoso que es realizarlo de esta forma:
![pg_queries1.jpg]()
Como vemos tenemos varios puntos que son cuellos de botella en este query, aparte de toda la data que se tiene que mover de forma poco eficiente, para ello vamos a reescribirlo de una forma más óptima y compararemos con un nuevo gráfico del EXPLAIN.
En esta nueva versión de nuestro query evitamos utilizar sub-consultas, en cambio hacemos un equivalente con left join y group by, si vemos el gráfico podremos notar la diferencia.
![pg_queries2.jpg]()
Podemos notar como el camino para obtener nuestro resultado ha sido mucho más corto lo que nos da un rendimiento mayor, con esto no queremos decir que debemos excluir a las sub-consultas de nuestras herramientas de trabajo, si no que debemos estar conscientes que pueden existir mejores caminos para lo que podamos estar planteando en el momento.
Esto no puede estar más lejos de la realidad, a pesar del avance en potencia de los equipos, las bases de datos son fundamentales para el rendimiento de las aplicaciones, por esta razón un query bien escrito y altamente optimizado puede significar varios segundos de carga que se ahorra en el sistema, si esto lo multiplicamos por la cantidad de usuarios concurrentes vemos como el costo y la potencia se estaban desaprovechando.
Optimizar Queries
La mejor forma de mejorar el rendimiento de nuestras bases de datos es iniciar con queries bien escritos, muchas veces encontramos que los queries no están bien escritos ya que no están tan optimizados como deberían estarlo, existen muchas causas para esto, una de ellas es la reutilización sin conciencia de código; con esto nos referimos a que si en algún momento hicimos un query que nos funciona con un left join lo seguiremos aplicando al aumentar la cantidad de tablas a consultar, cuando al modificarlo y cambiar algunas cláusulas por inner join pudiera acortar el camino y ahorrar consumo de procesador.
SQL es un lenguaje que a pesar que es bastante sencillo de leer, tiene muchas vertientes y muchas variaciones que nos permiten hacer algo que funcione de la mejor y de la peor forma, está de parte nuestra saber identificar si nuestra solución pertenece a una categoría u otra.
Para poder saber que estamos por el buen camino una de las cosas más importantes es estar actualizados, es decir, no podemos continuar codificando en SQL dentro de PostgreSQL como si fuese la primera versión cuando estamos en la versión 9.
Sobre Utilización de Sub-consultas
Esta es una de los errores más comunes que cometemos, y es que pensamos en un query como un conjunto de piezas que vamos engranando hasta obtener un resultado final, sin embargo este comportamiento es de alto impacto para el rendimiento de nuestra base de datos.
Veamos un ejemplo de este típico comportamiento:
SELECT tract_id ,(SELECT COUNT(*) FROM census.facts As F WHERE F.tract_id = T.tract_id) As num_facts ,(SELECT COUNT(*) FROM census.lu_fact_types As Y WHERE Y.fact_type_id IN (SELECT fact_type_id FROM census.facts F WHERE F.tract_id = T.tract_id)) As num_fact_types FROM census.lu_tracts As T;
Ahora, si vemos el gráfico del EXPLAIN de este query nos daremos cuenta lo costoso que es realizarlo de esta forma:
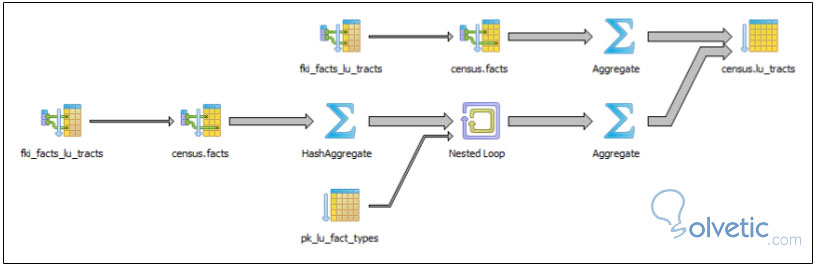
Como vemos tenemos varios puntos que son cuellos de botella en este query, aparte de toda la data que se tiene que mover de forma poco eficiente, para ello vamos a reescribirlo de una forma más óptima y compararemos con un nuevo gráfico del EXPLAIN.
SELECT T.tract_id, COUNT(f.fact_type_id) As num_facts, COUNT(DISTINCT fact_type_id) As num_fact_types FROM census.lu_tracts As T LEFT JOIN census.facts As F ON T.tract_id = F.tract_id GROUP BY T.tract_id;
En esta nueva versión de nuestro query evitamos utilizar sub-consultas, en cambio hacemos un equivalente con left join y group by, si vemos el gráfico podremos notar la diferencia.
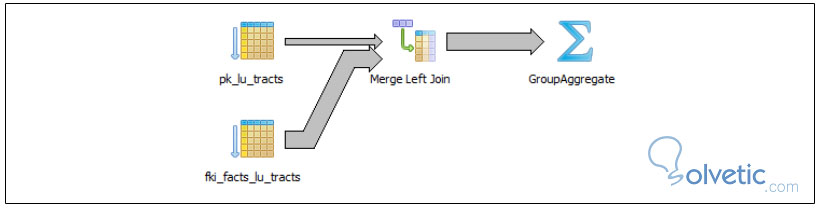
Podemos notar como el camino para obtener nuestro resultado ha sido mucho más corto lo que nos da un rendimiento mayor, con esto no queremos decir que debemos excluir a las sub-consultas de nuestras herramientas de trabajo, si no que debemos estar conscientes que pueden existir mejores caminos para lo que podamos estar planteando en el momento.



No es ninguna ayuda ya que no dice como optimizar la consulta...