Cuántas veces hemos requerido tener nuestros servicios, o mejor dicho, mantener nuestros servicios siempre disponibles, y cuantas veces nos ha pasado que se daña el disco duro de nuestro servidor y no tenemos respaldo, bien, pensando en esas circunstancias, he decidido crear este tutorial para garantizar que nuestros servidores o mejor dicho nuestros servicios siempre estén en línea.
Tomando en cuenta que el tutorial está pensado para personas avanzadas en Linux, no tocaré temas como la instalación del sistema base que en esta ocasión utilizaré CentOS 6 64 bits en su última actualización. Así mismo sólo mencionaré lo estrictamente necesario para el funcionamiento del clúster (servidores de alta disponibilidad).
También hago el comentario de que esta guía está dirigida a la necesidad de mantener el servicio web siempre activo, aunque lo he utilizado con otros servicios de forma exitosa, creo que como inicio o mejor dicho, como iniciación, lo más sencillo es crear un servidor web clúster.
Sin más preámbulo pasemos a lo bueno.
2. Disco Duro 80 GB
3. Procesador Celeron
4. Partición de datos para el clúster (el tamaño que deseen crear)
5. Sistema Operativo CentOS 6 (en su última actualización)
Si cumples los requisitos, comiencemos la instalación del cluster Linux.
Lo siguiente es instalar el DRBD para la sincronización de las particiones en ambos servidores, para esto es necesario ejecutar el en Shell las siguientes instrucciones:
[root@node1 ~] rpm -ivh http://elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm
[root@node1 ~] yum install -y kmod-drbd83 drbd83-utils(En lo personal yo utilizo el 8.3 ya que el 8.4 me dio problemas con algunas distribuciones)
[root@node1 ~] modprobe drbd
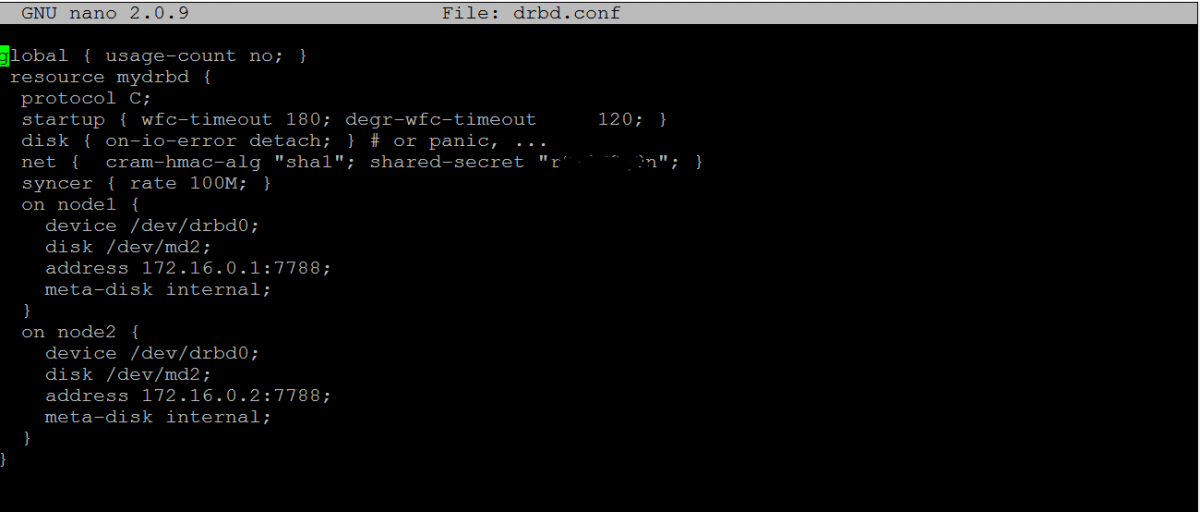
Se encuentra ubicado en /etc/drbd.d/mydrbd.res; siendo mydrbd.res el nombre del archivo y este puede ser modificado por cualquiera que deseemos, siempre y cuando mantengamos la extensión .res; este archivo de ser creado en ambos servidores, o bien, cuando este configurado correctamente el archivo, se copia al segundo nodo; la configuración sería más o menos la siguiente:
resource mydrbd {
#este es el nombre del recurso
protocol C;
startup {wfc-timeout 180; degr-wfc-timeout 120 ;}
#180 segundos de espera para el dispositivo esclavo, 120 segundos, si no contesta se degrada y queda como secundario
disk { on-io-error detach; }
net {cram-hmac-alg "sha1"; shared-secret "clave secreta";}
#En esta parte se especifica una clave con el cifrado sha1, esta clave es para la comunicación entre los dos nodos.
syncer {rate 100M ;}
#velocidad de sincronización, no importa que tengamos una tarjeta de red Gigabit, no funciona a 1000M, la velocidad máxima recomendada son 100M (lo he instalado con 10M y funciona de maravilla, un poco lenta la primera sincronización pero después no se ve la diferencia)
on node1 {
device /dev/drbd0;
#aquí especificamos cual es el dispositivo reservado para el drbd, podemos tener múltiples dispositivos para datos diferentes, o servicios diferentes, como SAMBA, MySQL, entre otros
disk /dev/md2; #se especifica la partición que se usara para drbd
address 172.16.0.1:7788;
#especificamos una ip fuera del rango de nuestra red, cabe mencionar que se debe conectar el cable de red directamente entre servidores, sin pasar por un switch o hub, si son tarjetas de red de modelo reciente no es necesario un cable crossover.
meta-disk internal;
}
on node2 {
#las especificaciones del segundo deben ser igual que las mimas que las del primero, solo cambia la dirección ip, debe ser el mismo puerto, esto se debe a que si tenemos 2 clúster juntos, estos entraran en conflicto y no funcionaran de forma adecuada, si deseamos tener múltiples clúster, se recomienda utilizar diversos puertos, está de más mencionar que estos puertos deben ser los mimos en ambos nodos.
device /dev/drbd0;
disk /dev/md2;
address 172.16.0.2:7788;
meta-disk internal;
}
}
/etc/hosts 192.168.1.1 nodo1 #nombre del nodo1 en segmento de red local 192.168.1.2 nodo2 #nombre del nodo2 en segmento de red local 172.16.0.1 node1 #nombre del nodo1 en segmento de red de sincronización 172.16.0.2 node2 #nombre del nodo2 en segmento de red de sincronización
[root@node1 ~] drbdadm create-md disk1
/etc/init.d/drbd start
drbdadm — –overwrite-data-of-peer primary disk1
Para esto ejecutamos:
cat /proc/drbdLa respuesta del comando anterior es algo como lo siguiente:
version: 8.3.15 (api:88/proto:86-97) GIT-hash: 0ce4d235fc02b5c53c1c52c53433d11a694eab8c build by phil@Build32R6, 2012-12-20 20:23:49 1: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r—n- ns:1060156 nr:0 dw:33260 dr:1034352 al:14 bm:62 lo:9 pe:78 ua:64 ap:0 ep:1 wo:f oos:31424 [==================>.] sync’ed: 97.3% (31424/1048508)K finish: 0:00:01 speed: 21,240 (15,644) K/sec #Aquí podemos ver que la sincronización va al 97.3 % y se especifica que este es el nodo primario y el secundario aparece como inconsistente ya que aún no termina la sincronización. #Una vez terminada, nuevamente corremos cat /proc/drbd y tenemos lo siguiente: version: 8.3.15 (api:88/proto:86-97) GIT-hash: 0ce4d235fc02b5c53c1c52c53433d11a694eab8c build by phil@Build32R6, 2012-12-20 20:23:49 1: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r—– ns:1081628 nr:0 dw:33260 dr:1048752 al:14 bm:64 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0 #Al devolver el mensaje UpToDate, nos da por enterados que la sincronización está completa y las particiones de drbd son exactamente iguales.
mkfs.ext3 /dev/drbd1Yo utilizo ext3 porque me ha dado buena estabilidad pero también podríamos utilizar ext4, no recomiendo utilizar ningún tipo de partición por debajo de ext3.
Hasta aquí ya somos capaces de montar manualmente la partición /dev/drbd1 en cualquier punto de montaje del sistema, en mi caso yo utilizo /home para el montaje ya que cada uno de los usuarios registrados en ambos nodos tienen sus propios directorios para páginas web, por lo tanto yo ejecuto:
mount –t ext3 /dev/drbd1 /homeY empiezo a crear los usuarios para la replicación de datos en ambos servidores, lo siguiente es la instalación de heartbeat, aplicación utilizada para monitorear entre sí los servidores y quien se encargará de hacer los cambios pertinentes si el primario cae por alguna razón y convierte al secundario en primario para asegurar la funcionalidad del Sistema.
Para la instalación de heartbeat solo se deben seguir los siguientes pasos. Se instala el repositorio para la descarga con el siguiente comando:
rpm –ivh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpmEditar el archivo:
epel.repo /etc/yum.repos.d/epel.repocambiar la línea # 6 ‘enable=1 por enable=0’; se pueden utilizar los editores vi o nano, según lo deseemos.
[epel] name=Extra Packages for Enterprise Linux 6 – $basearch #baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch mirrorlist=http://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch failovermethod=priority enabled=0 # Esta es la línea que debemos editar Instalar el heartbeat con el siguiente comando: yum –enablerepo=epel install heartbeat Una vez terminada la instalación nos dirá algo similar a: Installed: heartbeat.i686 0:3.0.4-1.el6 Complete!Una vez concluido el proceso de instalación lo siguiente es editar los 3 archivos esenciales para el funcionamiento del heartbeat; ubicados en /etc/ha.d
- authkeys
- ha.cf
- haresources
Abrimos el archivo authkeys con el siguiente comando:
vi /etc/ha.d/authkeysSe agregan las siguientes líneas:
auth 1 1 sha1 claveparaconexionentreheartbeats # En esta línea definimos cual será la clave para que se comuniquen entre si los heartbeat de cada nodo, puede ser igual a la utilizada en el drbd o diferente.Cambiamos los permisos del archivo authkeys para que solo puede ser leído por el root:
chmod 600 /etc/ha.d/authkeysAhora editamos el segundo archivo:
vi /etc/ha.d/ha.cfAgregamos las siguientes líneas:
logfile /var/log/ha-log #se habilita el log del sistema para futuros erres logfacility local0 keepalive 2 deadtime 30 #el Sistema espera 30 segundos para declarar el nodo1 como inoperable initdead 120 #el Sistema espera 120 segundos en el arranque del nodo para esperar al otro. bcast eth0 #se especifica la tarjeta Ethernet por la cual trasmitirá el comunicación entre servers, es muy importante prestar atención ya que aquí definimos cual tarjeta de red va a la red local y cual a la sincronización directa udpport 694 #se especifica el Puerto de sincronización, al igual que en el drbd podemos tener múltiples servidores y cada par con su respectivo puerto definido auto_failback off #al marcarlo como off prevenimos que el nodo1 una vez dañado y degradado regrese como primario o intente regresar haciendo así conflicto con otro nodo node node1 node2 #especificamos los nombres de ambos nodos.

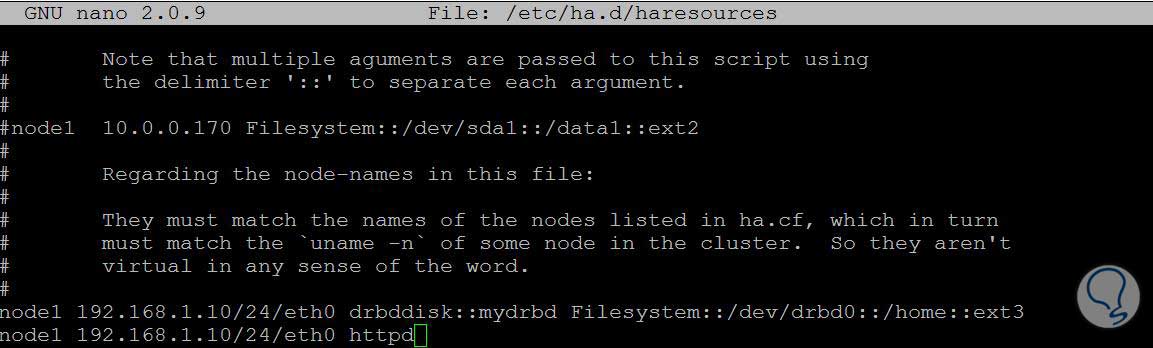
Para finalizar la configuración, debemos editar el archivo haresources con el comando:
vi /etc/ha.d/haresourcesAgregar las siguientes líneas:
node1 192.168.1.10/24/eth0 drbddisk::mydrbd Filesystem::/dev/drbd0::/home::ext3 #esta línea se encarga de montar la partición de datos en el nodo referenciado como primario node1 192.168.1.10/24/eth0 httpd #esta línea se encarga de definir el servicio del apache o servidor web hacia el nodo referenciado como primario
Se deben copiar los 3 archivos al nodo2, el siguiente comando se encargara de ello:
scp -r /etc/ha.d/root@node2:/etc/Se debe editar el archive httpd.conf para que escuche las peticiones de la ip virtual, en este caso la 192.168.1.10:
vi /etc/httpd/conf/httpd.confSe agrega o modifica la línea Listen 192.168.1.10:80
Se copia el archivo modificado al segundo servidor:
scp /etc/httpd/conf/httpd.conf root@node2:/etc/httpd/conf/Iniciamos el servicio de heartbeat en ambos nodos:
/etc/init.d/heartbeat startCon esto ya tenemos listo nuestro servidor de alta disponibilidad, solo es cuestión de entrar a nuestro navegador de internet y poner la ip 192.168.1.10 o bien instalar algún panel de su elección para administración de dominios y generar los usuarios correspondientes para el acceso a las paginas o dominios registrados en el server.
El servidor de alta disponibilidad puede ser utilizado como ya lo había mencionado al inicio de este tutorial como: servidor de correo electrónico, servidor web, servidor de bases de datos, servidor samba entre otros; así mismo nos ayuda a la prevención de la perdida de información por fallas de hardware, y lo podemos reforzar más con raids en las unidades de disco, ya sea por hardware o software, nunca esta demás tener discos en raid para mantener el sistema.
No obstante el servidor de alta disponibilidad no está exento de problemas o errores, cuando se degrada un nodo podemos acudir al log del heartbeat para ver qué fue lo que sucedió, esto lo logramos accediendo al archivo asignado en la configuración del haresources en /etc/ha.d
De igual forma puede ocurrir que al reiniciar ambos servidores por alguna razón no inicien como primario/secundario e inicien como primario/unknow y unknow/secundario.

Para solucionar esto debemos seguir los siguientes pasos.
En el Shell del nodo caído tecleamos :
drbdadm secondary resourcePosteriormente:
drbdadm disconnect resourceY después:
drbdadm -- --discard-my-data connect resourcePor último, en el nodo sobreviviente, o primario tecleamos:
drbdadm connect resourceAhora iniciará la resincronización de los nodos a partir del nodo sobreviviente hacia el nodo caído, esto iniciando de forma inmediata al pulsar la tecla “Enter” en la instrucción 4.
Lo sucedido aquí es conocido como un Split-brain, esto sucede cuando por alguna razón el nodo primario falla y es degradado, una vez que esto sucede es altamente recomendable revisar y analizar a profundidad el nodo caído y antes de volver a incorporarlo al clúster solucionar cualquier problema existente, también podría ser necesario el reinstalar todo el sistema operativo de este nodo, y sin problema alguno incorporarlo al clúster como secundario para la sincronización y si fuera el caso, una vez sincronizado cambiarlo a primario.
Por ultimo quisiera hacer un poco de énfasis en la revisión periódica de la salud del clúster, que bien sabemos es para alto performance siempre es bueno estar un paso delante de los desastres informáticos; ya que como personal de IT cae en nosotros la responsabilidad de cuidar los datos de la empresa o empresas a la o las que pertenezcamos, como nota adicional, creo que no está demás recomendar tener siempre un respaldo en alguna unidad alterna a los nodos y así tener garantizada la seguridad de la información.










Esto es la leche!! que bueno Juan, gracias por compartirlo, me quedaba parado montando una serie de clusters de Linux.