En tutoriales pasados entramos de lleno con CQL y la forma en la cual nos ayuda a la gestión de Cassandra, vimos las operaciones básicas para los keyspaces y las tablas en Cassandra, pudimos aplicarlos para la creación de una estructura inicial en la Base de Datos, sin embargo existen una cantidad considerable de conceptos avanzados que necesitamos saber para sacarle el máximo provecho a Cassandra.
Estos conceptos o característica por llamarlos de alguna forma, nos permiten lograr funcionalidades distintas en nuestras tablas, dándonos un abanico de posibilidades mucho mayor que el resto de las otras Base de Datos NoSQL.
Anteriormente creamos algunas tablas y utilizamos valores como text o date para nuestras columnas, pero esto no es todo lo que CQL tiene disponible, veamos los tipos de datos con los que contamos para nuestras operaciones:
Como vemos existen muchos tipos de datos que podemos reconocer si venimos del mundo relacional, como otros que veremos por primera vez y que hacen que Cassandra se destaque por encima de otras Bases de Datos.
En Cassandra no solo tenemos tipos de datos para nuestras tablas, gracias a CQL podemos asignarle a las tablas dentro de nuestra Base de Datos propiedades las cuales nos ayudan enormemente en tareas de mantenimiento y desarrollo, veamos que tenemos disponible.
Ya sabemos entonces con que contamos, tanto a nivel de tipos de datos y propiedades, es hora entonces de aplicar algunas de las cosas aprendidas a nuestras tablas en Cassandra.
Primero vamos a crear una tabla sencilla a la cual le aplicaremos la propiedad de comentarios, veamos la sintaxis que utilizaremos para la misma:
Como ya sabemos la consola de comandos no nos devuelve nada excepto que no hay ningún error, pero si queremos ver estos cambios podemos dirigirnos a nuestro OpsCenter y verificar que todo ha salido de manera correcta:
![manejo-avanzado-tablas-cassandra-2.jpg]()
Como vemos podemos ver nuestro comentario y otras propiedades con sus valores por defecto. Es importante mencionar que la definición del resto de las propiedades en Cassandra es bastante sencillo, como pudimos ver con el ejemplo anterior, utilizando la sintaxis WITH podemos hacerlo sin ningún problema.
Vamos a realizar otro ejemplo donde vamos a definir las propiedades compression y compaction pero para ello es importante conocer que estas tienen una serie de sub opciones para su uso, veamos para compression que debemos conocer:
Manipular las opciones de compresión puede llevarnos a un aumento significativo del rendimiento, inclusive muchas implementaciones de Cassandra están con esos valores por defecto, pero para su perfección es necesario usar estos valores. Veamos ahora que debemos conocer para compaction:
Estas son algunas de las opciones más importantes para estas propiedades, lo que es importante mencionar es que para la definición de estas opciones debemos utilizar una sintaxis JSON para que sean válidas, veamos entonces un ejemplo de la inclusión de estas dos propiedades:
En el tutorial pasado pudimos ver que a raíz de definir más de una llave primaria estas son creadas como clustering keys y nos indican la forma en que Cassandra ordena la información, por defecto el orden es definido de manera ascendente y hacer una consulta por orden descendente podría causarnos problemas de rendimiento, sin embargo Cassandra tiene una solución para cualquier problema y es con la sentencia CLUSTERING ***** BY. Veamos cómo utilizarlo.
Como pudimos ver fue bastante sencillo solucionar este problema con solo una simple línea, pero lo más importante es que pudimos extender nuestro conocimiento en lo que respecta al manejo de las tablas en Cassandra, con lo cual finalizamos este tutorial, donde hemos cubierto todo lo que necesitamos saber para una creación óptima de tablas en Cassandra.
Estos conceptos o característica por llamarlos de alguna forma, nos permiten lograr funcionalidades distintas en nuestras tablas, dándonos un abanico de posibilidades mucho mayor que el resto de las otras Base de Datos NoSQL.
Tipos de datos
Anteriormente creamos algunas tablas y utilizamos valores como text o date para nuestras columnas, pero esto no es todo lo que CQL tiene disponible, veamos los tipos de datos con los que contamos para nuestras operaciones:
ascii
Cadena de caracteres de tipo US-ASCII.
bigint
Valor entero de 64 bits de longitud.
blob
Tipo de dato expresado como un hexadecimal en la consola de comandos de CQL, adicionalmente posee no posee validación y se basa en bytes arbitrarios.
boolean
El clásico tipo de dato booleano donde sus valores pueden ser true o false.
counter
counter es un tipo de dato nuevo para los que venimos del mundo relacional e indica que es de 64 bits distribuido.
decimal
Otro tipo de dato que podemos reconocer, el cual nos da precisión decimal para nuestra información.
double
Tipo de dato de coma flotante pero en base a 64 bits.
float
Al igual que el anterior es un tipo de dato de coma flotante pero en base a 32 bits.
inet
Este tipo es bastante particular y muy útil a la vez y nos permite almacenar una cadena de caracteres de una dirección IP, soporta tanto el formato IPV4 como IPV6.
int
El clásico tipo de dato entero que soporta números de hasta 32 bits.
list
Otro tipo de dato que hace su debut en Cassandra y nos permite almacenar una colección ordenada de elementos.
map
Al igual que list es otro tipo de dato nuevo, y nos permite almacenar un array asociativo, lo cual nos resulta muy útil para el desarrollo de aplicaciones.
set
Similar a el tipo de dato list, almacena una colección de elementos pero sin un orden en específico.
text
Almacena una cadena de caracteres encodeada.
timestamp
Tipo de dato que almacena fecha y hora, encodeada como un entero de 8 bytes.
varint
Tipo de dato de precisión para enteros arbitrarios.
Como vemos existen muchos tipos de datos que podemos reconocer si venimos del mundo relacional, como otros que veremos por primera vez y que hacen que Cassandra se destaque por encima de otras Bases de Datos.
Propiedades de las tablas
En Cassandra no solo tenemos tipos de datos para nuestras tablas, gracias a CQL podemos asignarle a las tablas dentro de nuestra Base de Datos propiedades las cuales nos ayudan enormemente en tareas de mantenimiento y desarrollo, veamos que tenemos disponible.
Caching
Esta propiedad nos brinda optimización de la memoria cache. Los niveles disponibles para esta propiedad son all o todos, keys_only o solo llaves, rows_only o solo filas y none o ninguno. Todas las opciones son bastante útiles, sin embargo row_only debe ser usada con cuidado ya que Cassandra coloca una cantidad de data considerable en memoria cuando esa opción es utilizada.
Comment
Una opción que está presente en el modelo relacional, y es utilizada por administradores o desarrolladores para hacer notas y resaltar detalles importantes en las tablas.
Compaction
Esta propiedad permite definir la estrategia para el manejo de las mentables, pueden ser de tos tipos: La primera SizeTiered la cual se dispara cuando la tabla pasa un límite, la ventaja de utilizar esta estrategia es que no degrada el rendimiento de escritura, sin embargo tiene una desventaja es que ocasionalmente usa el doble del tamaño de la data en el disco, resultando en un rendimiento de lectura pobre. La segunda estrategia es LeveledCompaction y funciona en distintos niveles a lo largo del tiempo, uniendo las tablas con otras más largas, resultando en rendimiento de lectura bastante buenos.
Compression
Esta propiedad determina como la información será comprimida. Podemos seleccionar obtener prestaciones en velocidad o espacio, donde mayor la velocidad, menor espacio en el disco es salvado.
Gc_grace_seconds
Esta propiedad define el tiempo de espera para remover la información de los tombstones. Por defecto es de 10 días.
Populate_io_cache_on_flush
Esta propiedad es deshabilitada por defecto, y solo debemos activarla si esperemos que toda la información quepa en la memoria cache.
Read_repair_chance
Una propiedad bastante interesante que indica un número entre 0 y 1.0 especificando la probabilidad de reparar la información cuando el quorum no es alcanzado. El valor por defecto es 0.1.
Replicate_on_write
Esta propiedad aplica solo para tablas de tipo counter. Cuando es definida las réplicas escriben a todas las réplicas afectadas, ignorando el nivel de consistencia especificado.
Ya sabemos entonces con que contamos, tanto a nivel de tipos de datos y propiedades, es hora entonces de aplicar algunas de las cosas aprendidas a nuestras tablas en Cassandra.
Primero vamos a crear una tabla sencilla a la cual le aplicaremos la propiedad de comentarios, veamos la sintaxis que utilizaremos para la misma:
CREATE TABLE articulos ( titulo text,contenido text,categoria text,PRIMARY KEY (titulo)) WITH comment = 'Tabla para almacenar la informacion de articulos';Abrimos nuestra consola de comandos CQL y creamos nuestra tabla con la propiedad mencionada, veamos como luce:
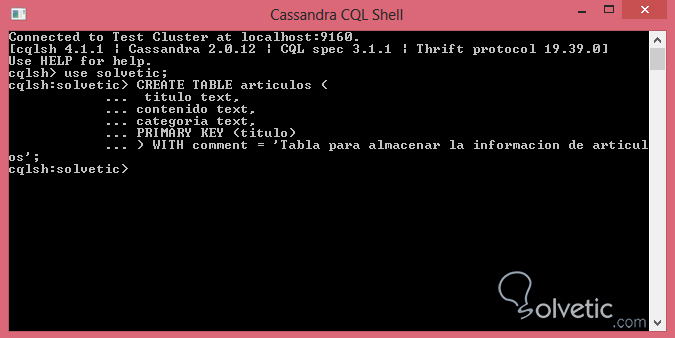
Como ya sabemos la consola de comandos no nos devuelve nada excepto que no hay ningún error, pero si queremos ver estos cambios podemos dirigirnos a nuestro OpsCenter y verificar que todo ha salido de manera correcta:

Como vemos podemos ver nuestro comentario y otras propiedades con sus valores por defecto. Es importante mencionar que la definición del resto de las propiedades en Cassandra es bastante sencillo, como pudimos ver con el ejemplo anterior, utilizando la sintaxis WITH podemos hacerlo sin ningún problema.
Compresión y compactación
Vamos a realizar otro ejemplo donde vamos a definir las propiedades compression y compaction pero para ello es importante conocer que estas tienen una serie de sub opciones para su uso, veamos para compression que debemos conocer:
Sstable_compression
Esta opción especifica el algoritmo de compresión a utilizar, sus valores son: LY4Compressor, SnappyCompressor, y DeflateCompressor.
Chunck_length_kb
Las tablas son comprimidas por bloques. Valores más largos por lo general proveen una compresión mejor pero aumentan el tamaño de la información para lectura. Por defecto esta opción es seteada a 64 kb.
Manipular las opciones de compresión puede llevarnos a un aumento significativo del rendimiento, inclusive muchas implementaciones de Cassandra están con esos valores por defecto, pero para su perfección es necesario usar estos valores. Veamos ahora que debemos conocer para compaction:
Enabled
Determina si la propiedad correrá en la tabla aunque por defecto todas las propiedades tienen compaction habilitado.
Class
Aquí definiremos el tipo de estrategia para el manejo de las tablas.
min_threshold
Este valor está disponible con la estrategia SizeTiered y representa el número mínimo de tablas necesitadas para empezar un proceso de compactación. Es definido por defecto en 4.
max_threshold
Disponible de igual forma en la estrategia SizeTiered y define el número máximo de tablas procesadas en la compactación. Es definido por defecto en 32.
Estas son algunas de las opciones más importantes para estas propiedades, lo que es importante mencionar es que para la definición de estas opciones debemos utilizar una sintaxis JSON para que sean válidas, veamos entonces un ejemplo de la inclusión de estas dos propiedades:
CREATE TABLE tabla_para_propiedades (id int,nombre text,propiedad text,numero varint,PRIMARY KEY (id) ) WITHcompression = { 'sstable_compression' : 'DeflateCompressor','chunk_length_kb' : 64}ANDcompaction = { 'class' : 'SizeTieredCompactionStrategy', 'min_threshold' : 6};Como vemos hemos cambiado el tipo de compresión y hemos definido el tamaño para la misma, adicionalmente para compaction hemos dejado la estrategia usual con el valor class y hemos definido el min_threshold como 6 aumentado así el valor por defecto, para finalizar veamos como luce esto cuando lo ejecutamos en nuestra consola de comandos: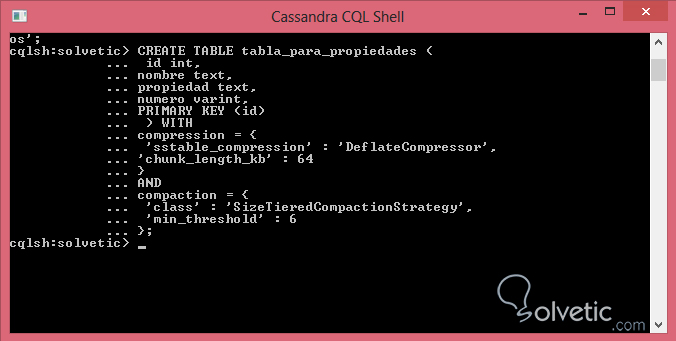
Ordenando la data en el cluster
En el tutorial pasado pudimos ver que a raíz de definir más de una llave primaria estas son creadas como clustering keys y nos indican la forma en que Cassandra ordena la información, por defecto el orden es definido de manera ascendente y hacer una consulta por orden descendente podría causarnos problemas de rendimiento, sin embargo Cassandra tiene una solución para cualquier problema y es con la sentencia CLUSTERING ***** BY. Veamos cómo utilizarlo.
CREATE TABLE usuarios_ordenados (usuario text,fecha timestamp,salario float,departamento text,supervisor text,PRIMARY KEY (usuario, fecha)) WITH CLUSTERING ***** BY (fecha DESC);Vamos a ejecutar nuestra sintaxis en la consola de comandos y veamos como luce:
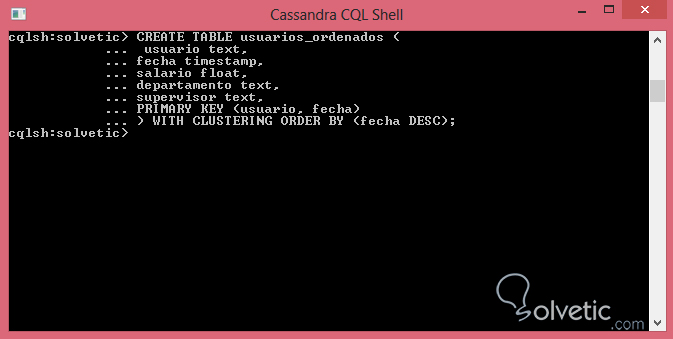
Como pudimos ver fue bastante sencillo solucionar este problema con solo una simple línea, pero lo más importante es que pudimos extender nuestro conocimiento en lo que respecta al manejo de las tablas en Cassandra, con lo cual finalizamos este tutorial, donde hemos cubierto todo lo que necesitamos saber para una creación óptima de tablas en Cassandra.



Genial tutorial, gracias!