CQL o Cassandra Query Language es el lenguaje que usa para la interacción con Cassandra y es la forma en la cual se recomienda que se realice la interacción. Posee una similitud bastante grande con el conocido SQL ya que uno de sus objetivos principales es que el usuario se sienta bastante comodo trabajando con el mismo al parecerse a este, sin embargo posee una gran diferencia y es que CQL no soporta joins o subqueries.
Pero esta diferencia no es relevante ya que la forma en que Cassandra trabaja y por ser una Base de Datos NoSQL, no es necesario tener estas características. Lo que es importante y debemos manejar es la forma en la cual podemos interactuar con Cassandra a través del Shell de comandos CQL.
En el tutorial pasado estuvimos viendo como está conformado la estructura de Cassandra y adicionalmente vimos el OpsCenter, una interfaz web que nos ayuda a visualizar varios aspectos de nuestra Base de Datos pero que carece del resto de funcionalidades para trabajar de forma correcta con la misma.
Para trabajar con la Base de Datos vamos a utilizar la consola de comandos de CQL, la cual la podemos conseguir en nuestra instalación de Cassandra y al ejecutarse debe lucir de la siguiente forma:
Ya con nuestra consola de comandos activa y corriendo ya podemos empezar a vaciar instrucciones en Cassandra, sin embargo antes de empezar a crear tablas y trabajar con las mismas, debemos crear el contenedor para estas, y si recordamos de tutoriales pasados este contenedor es llamado el keyspace.
El keyspace no solo tiene como funcionalidad ser el contenedor de las tablas, el mismo es el encargado de definir el factor y estrategia de replicación, vamos entonces a crear nuestro primer keyspace mediante la consola de comandos, para ello vamos a ejecutar las siguientes líneas:
Para ejecutar la sentencia CQL para la creación del keyspace en nuestra consola de comandos podemos escribir línea por línea para llevar una organización mejor de nuestra sentencia, solo debemos saber que al finalizar una sentencia con el punto y coma, es allí cuando se hará efectiva:
Si hemos deseamos cambiar los valores de nuestro keyspace podemos hacerlo con ALTER, esto es útil cuando migramos a un ambiente en producción y necesitamos cambiar el factor de replicación, veamos como luce nuestra sentencia CQL con el ALTER:
La creación de tablas dentro de Cassandra es bastante similar a cuando lo hacemos en modelos relacionales, sin embargo tiene algunas diferencias, lo primero que debemos hacer y para ahorrarnos tener que indicar el keyspace es usar el mismo. Para ello usamos la palabra reservada USE:
Ya con esto último verificado, vamos a crear nuestra primera tabla, donde como comentamos la sintaxis es bastante similar a SQL, veamos como luce nuestra tabla de usuarios:
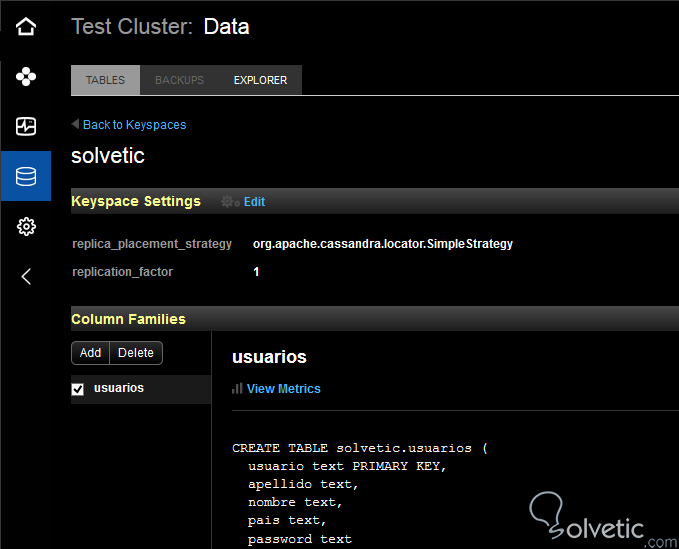
Como vemos nos devuelve el valor cero, lo cual está bien ya que no hemos insertado datos en la misma. La otra forma que tenemos y es si somos más visuales es de visualizar la tabla en el OpsCenter, para ello ingresamos y nos dirigimos en la sección Data, seleccionamos el keyspace y allí tendremos nuestras tablas creadas:
La llave primaria es necesaria cuando estamos creando la tabla, la cual a diferencia del modelo relacional pueden ser más de dos columnas, si tenemos una sola llave primaria podemos definir la misma luego del tipo de dato:
Como vemos entonces el clustering ***** by será mediante la columna fecha de manera ASC, y como pudimos ver fue bastante sencillo de crear esta funcionalidad en nuestra tabla. Cassandra adicionalmente nos permite combinar el id de una fila con información de otra columna en porciones mucho más pequeñas. Por ejemplo, imaginemos que cada usuario sube más de 20 tutoriales, entonces lo más recomendable sería dividir esta información por tutoriales, veamos cómo se vería nuestra nueva tabla:
Además de crear nuestra tabla y poder dotarla de algunas funcionalidades bastante útiles para nuestro modelo de datos, es importante conocer las otras operaciones que podemos realizar en la misma. La primera de ellas es la modificación de la misma, podemos modificar desde el tipo de dato de las columnas (siempre que sea válido), añadir o eliminar columnas, vaciar la información de la tabla y por supuesto eliminar la tabla.
Vamos a tomar de ejemplo la tabla tutorial_por_usuarios para aplicar el resto de las operaciones, primero vamos a modificar el tipo de dato de la columna categoría de text por blob, veamos:
Vemos entonces los cambios aplicados, nuestra columna categoría con un nuevo tipo de dato y una nueva columna llamada ruta_img. Por último para completar el ciclo de vida de la tabla veamos las operaciones restantes destructivas, donde con TRUNCATE podemos vaciar toda la información en nuestra tabla:
Pero esta diferencia no es relevante ya que la forma en que Cassandra trabaja y por ser una Base de Datos NoSQL, no es necesario tener estas características. Lo que es importante y debemos manejar es la forma en la cual podemos interactuar con Cassandra a través del Shell de comandos CQL.
Consola de comandos CQL
En el tutorial pasado estuvimos viendo como está conformado la estructura de Cassandra y adicionalmente vimos el OpsCenter, una interfaz web que nos ayuda a visualizar varios aspectos de nuestra Base de Datos pero que carece del resto de funcionalidades para trabajar de forma correcta con la misma.
Para trabajar con la Base de Datos vamos a utilizar la consola de comandos de CQL, la cual la podemos conseguir en nuestra instalación de Cassandra y al ejecutarse debe lucir de la siguiente forma:
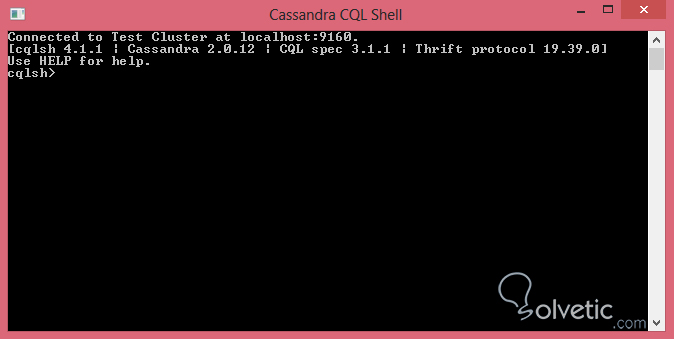
Ya con nuestra consola de comandos activa y corriendo ya podemos empezar a vaciar instrucciones en Cassandra, sin embargo antes de empezar a crear tablas y trabajar con las mismas, debemos crear el contenedor para estas, y si recordamos de tutoriales pasados este contenedor es llamado el keyspace.
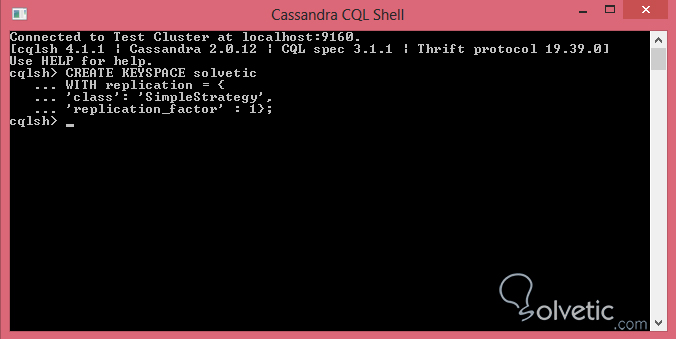
El keyspace no solo tiene como funcionalidad ser el contenedor de las tablas, el mismo es el encargado de definir el factor y estrategia de replicación, vamos entonces a crear nuestro primer keyspace mediante la consola de comandos, para ello vamos a ejecutar las siguientes líneas:
CREATE KEYSPACE solveticWITH replication = {'class': 'SimpleStrategy','replication_factor' : 1};Primero creamos nuestro keyspace llamado solvetic y con WITH definimos los valores para la replicación, en este caso hemos escogido SimpleStrategy como la estrategia, la cual se encarga de replicar la información al siguiente nodo disponible. Adicionalmente hemos definido el factor replicación como 1, el cual creará una sola copia de la información, como estamos en desarrollo es lo más recomendable, si especificamos un valor mayor 3 podemos presentar problemas de rendimiento ya que solo tenemos un cluster y un nodo.Para ejecutar la sentencia CQL para la creación del keyspace en nuestra consola de comandos podemos escribir línea por línea para llevar una organización mejor de nuestra sentencia, solo debemos saber que al finalizar una sentencia con el punto y coma, es allí cuando se hará efectiva:
Si hemos deseamos cambiar los valores de nuestro keyspace podemos hacerlo con ALTER, esto es útil cuando migramos a un ambiente en producción y necesitamos cambiar el factor de replicación, veamos como luce nuestra sentencia CQL con el ALTER:
ALTER KEYSPACE solveticWITH REPLICATION = { 'class' : 'SimpleStrategy','replication_factor' : 3};Adicionalmente, podemos cambiar la estrategia de replicación por NetworkTopologyStrategy, la cual permite definir el factor de replicación para distintos centros de datos, veamos:
CREATE KEYSPACE solvetic WITH replication = { 'class': 'NetworkTopologyStrategy', 'DC1' : 1, 'DC2' : 3};Como vemos hemos cambiado nuestra estrategia y hemos definido para el centro de datos 1 o DC1 el factor de replicación 1, y para DC2 o centro de datos 2, el factor 3. Así como podemos crear y modificar, podemos eliminar nuestro keyspace, esto lo hacemos con la palabra DROP al igual que en el SQL tradicional:DROP KEYSPACE solvetic;Ya visto los aspectos básicos de los keyspaces en Cassandra, es momento de crear las tablas dentro de nuestro keyspace.
Creación de tablas
La creación de tablas dentro de Cassandra es bastante similar a cuando lo hacemos en modelos relacionales, sin embargo tiene algunas diferencias, lo primero que debemos hacer y para ahorrarnos tener que indicar el keyspace es usar el mismo. Para ello usamos la palabra reservada USE:
USE solvetic;Al utilizar USE todo lo que hagamos de ahora en adelante será dentro de ese keyspace, por lo que no debemos preocuparnos por indicarlo, y en la consola de comandos nos debe especificar el keyspace en el cual estamos:
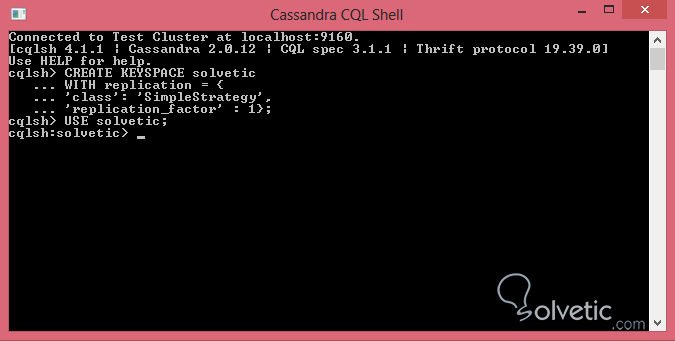
Ya con esto último verificado, vamos a crear nuestra primera tabla, donde como comentamos la sintaxis es bastante similar a SQL, veamos como luce nuestra tabla de usuarios:
CREATE TABLE usuarios (usuario text,password text,nombre text,apellido text,pais text,PRIMARY KEY (usuario));Como vemos es bastante sencillo, mucho más que el SQL convencional, definimos las columnas y su tipo de dato, por último definimos la llave primaria y ejecutamos. La consola de comandos no nos devuelve nada, simplemente no nos da error, pero si queremos verificar que fue creada nuestra tabla podemos hacer dos cosas; podemos ejecutar un SELECT a nuestra tabla, veamos:
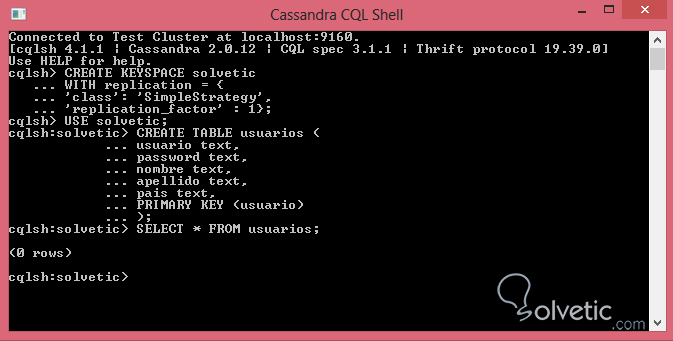
Como vemos nos devuelve el valor cero, lo cual está bien ya que no hemos insertado datos en la misma. La otra forma que tenemos y es si somos más visuales es de visualizar la tabla en el OpsCenter, para ello ingresamos y nos dirigimos en la sección Data, seleccionamos el keyspace y allí tendremos nuestras tablas creadas:
La llave primaria es necesaria cuando estamos creando la tabla, la cual a diferencia del modelo relacional pueden ser más de dos columnas, si tenemos una sola llave primaria podemos definir la misma luego del tipo de dato:
CREATE TABLE usuarios (usuario text PRIMARY KEY,password text,nombre text,apellido text,pais text);La primera llave primaria que se define en Cassandra es llamada partition key o llave de partición, y es la llave que identifica cada fila de datos. Las llaves siguientes que especifiquemos serán las clustering keys y son las que influyen en la manera en la cual Cassandra ordena la información, veamos entonces como expresamos lo explicado en nuestra sentencia CQL:
CREATE TABLE tutorial (usuario text,fecha timestamp,titulo text,categoria text,contenido text,PRIMARY KEY (usuario, fecha));Esto nos ha creado nuestra tabla tutorial, con nuestra partition key llamada usuario y la clustering key fecha, ingresemos a OpsCenter para demostrar como la columna fecha será el criterio que utilizará Cassandra para ordenar la información:
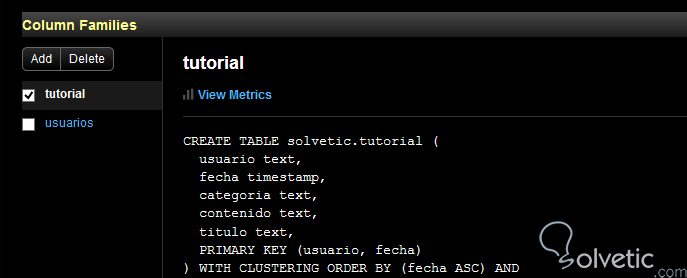
Como vemos entonces el clustering ***** by será mediante la columna fecha de manera ASC, y como pudimos ver fue bastante sencillo de crear esta funcionalidad en nuestra tabla. Cassandra adicionalmente nos permite combinar el id de una fila con información de otra columna en porciones mucho más pequeñas. Por ejemplo, imaginemos que cada usuario sube más de 20 tutoriales, entonces lo más recomendable sería dividir esta información por tutoriales, veamos cómo se vería nuestra nueva tabla:
CREATE TABLE tutorial_por_usuarios (usuario text,fecha timestamp,titulo text,categoria text,contenido text,PRIMARY KEY ((usuario, titulo), fecha));Lo que debemos tener en cuenta cuando construimos este estilo de tablas es que no podremos acceder a los tutoriales sino especificamos el nombre del usuario y el título, así que es algo que debemos tener en cuenta cuando estamos construyendo nuestro modelo para nuestra Base de Datos, si es lo más óptimo para nuestra operación.
Operaciones adicionales
Además de crear nuestra tabla y poder dotarla de algunas funcionalidades bastante útiles para nuestro modelo de datos, es importante conocer las otras operaciones que podemos realizar en la misma. La primera de ellas es la modificación de la misma, podemos modificar desde el tipo de dato de las columnas (siempre que sea válido), añadir o eliminar columnas, vaciar la información de la tabla y por supuesto eliminar la tabla.
Vamos a tomar de ejemplo la tabla tutorial_por_usuarios para aplicar el resto de las operaciones, primero vamos a modificar el tipo de dato de la columna categoría de text por blob, veamos:
ALTER TABLE tutorial_por_usuarios ALTER categoria TYPE blob;Para añadir columnas es bastante similar a como lo haríamos con SQL, con la palabra ADD realizamos esta operación, donde agregaremos una columna llamada ruta_img:
ALTER TABLE tutorial_por_usuarios ADD ruta_img text;Ejecutada nuestra sentencia en la consola de comandos nos dirigimos a OpsCenter para visualizar los cambios aplicados a nuestra tabla:
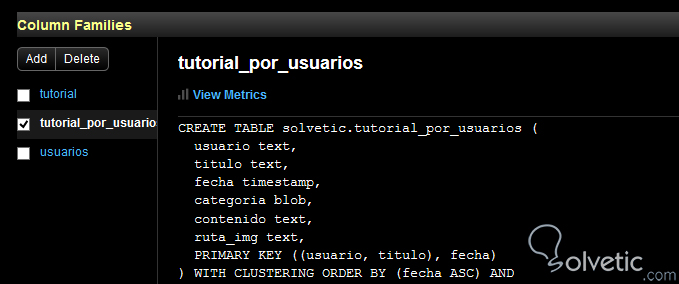
Vemos entonces los cambios aplicados, nuestra columna categoría con un nuevo tipo de dato y una nueva columna llamada ruta_img. Por último para completar el ciclo de vida de la tabla veamos las operaciones restantes destructivas, donde con TRUNCATE podemos vaciar toda la información en nuestra tabla:
TRUNCATE tutorial_por_usuarios;Por último, eliminamos nuestra tabla con el conocido DROP TABLE:
DROP TABLE tutorial_por_usuarios;Como vemos la semejanza con SQL es bastante, lo cual es el objetivo principal de Cassandra, que los usuarios se sientan cómodos trabajando con el mismo. Con esto finalizamos este tutorial, donde pudimos ver que Cassandra a pesar de ser teóricamente mucho más compleja que las Bases de Datos relacionales convencionales, en la práctica demuestra que no solo es poderosa y versátil sino que es sumamente sencilla de manejar y de manipular para la creación de nuestro modelo de datos.

