Cassandra es una Base de Datos NoSQL poderosa y escalable. Es de código libre y su arquitectura está diseñada como un sistema distribuido donde todos los nodos son iguales dentro de la misma, permitiendo así que la data sea distribuida a lo largo de todos los nodos en el cluster.
El almacenamiento en Cassandra está definido como llave/valor donde una llave puede mapear a uno o más valores. Es una Base de Datos orientada a registros por filas, donde cada fila está identificada por su llave y la particularidad de este sistema es que una fila puede ser almacenada en más de un nodo.
Antes de pasar a la instalación de Cassandra en nuestro sistema, debemos conocer un poco la arquitectura de esta Base de Datos, de esta forma sabremos con que contamos y que podemos lograr.
Cuando hablamos de replicación de la información, uno de las primeras preguntas que nos hacemos es: ¿Cuántas copias necesitamos? Esto en Cassandra no es una pregunta sencilla de responder, pero lo que debemos tener en cuenta es que este factor nos indica el número de nodos que son almacenados en una misma fila.
Por ejemplo, un factor de replicación de 2 nos garantiza que habrás dos copias de la información de los nodos en el cluster. Escoger el valor dos para el factor de replicación está bien para cubrir fallas en un nodo en el ambiente de desarrollo y puede ser lo mínimo para ambientes de producción, ya que si un nodo cae el otro se encargará de manejar todas las peticiones, así que es algo que debemos pensar con detenimiento antes de implementarlo.
El protocolo usado por Cassandra para compartir la locación de los nodos y la información de estos en el cluster es llamado Gossip. Donde estos nodos están constantemente “murmurando” e intercambiando información con hasta 3 nodos en el cluster.
Este protocolo como otros tiene sus reglas para enviar peticiones a otros nodos, donde podemos ver tres pasos para el mismo, y cada nodo repite siempre estos pasos:
1- Murmurar a un nodo activo al azar.
2- Iniciar un murmuro hacia un nodo hacia abajo al azar.
3- Este paso es opcional y define que si el nodo seleccionado en el paso uno, no es un nodo semilla, murmurar a otro nodo semilla aleatorio.
Pero para mover la información y realizar la comunicación entre los nodos Cassandra usa un componente llamado Snitch, veamos a que se refiere.
Básicamente este componente se encarga de manejar el movimiento de la información entre nodos tomando otros nodos para consultas y replicación basadas en métricas varias. Esta configuración es la misma para todos los nodos dentro del cluster, sin embargo puede variar en su tipo, veamos cuales tenemos disponibles:
La instalación de Cassandra la realizaremos en un equipo con Windows 8, en el cual debemos cumplir con ciertos requerimientos antes, veamos que necesitamos:
1- Necesitamos tener al menos Java 7 instalado en nuestro sistema, sino lo tenemos podemos descargar la versión más reciente en el siguiente enlace.
2- Necesitamos adicionalmente Microsoft Visual C++ 2008 Redistributable Package (x86).
3- Por último conexión a Internet para poder descargar el paquete de DataStax.
Ya con nuestros requisitos revisados, vamos a irnos a la página del proyecto y buscaremos la versión de 32 o 64 bits que se adapte a nuestro sistema:
![introduccion-cassandra.jpg]()
Si queremos darle un vistazo a la documentación de conectividad de Cassandra con los diferentes lenguajes de programación podemos bajar en la página y ver que necesitamos para lo mismo. Luego de la descarga, instalamos como cualquier aplicación de Windows. Donde es importante mencionar que luego de esta instalación, Cassandra nos creará por defecto un cluster de pruebas.
Con la instalación, varias herramientas son instaladas en nuestro sistema, una de ellas es la interfaz web de Cassandra llamada OpsCenter, a la cual podemos ingresar si colocamos en nuestro navegador la siguiente dirección:
Lo primero que nos encontramos al entrar en esta interfaz es la sección de Dashboard, donde podemos visualizar varias métricas de rendimientos como salud del nodo, capacidad de almacenamiento o peticiones de escritura:
![introduccion-cassandra-2.jpg]()
En esta interfaz podemos crear un nuevo cluster, para ello nos dirigimos a la parte superior derecha, y pulsamos New Cluster, lo cual nos abrirá la siguiente pantalla:
Ingresamos los datos solicitados y pulsamos en build cluster, adicionalmente a esto podremos añadir nodos por igual en el desplegable de Cluster Actions, en la parte superior derecha. En la sección Nodes, podemos ver los nodos disponibles y los centros de datos, así como ciertos parámetros como la salud, el tamaño de la data e inclusive las alertas generadas:
![introduccion-cassandra-4.jpg]()
En la sección Activities podemos ver un listado de las actividades realizadas en el cluster, así como un log de eventos, algo bastante útil cuando somos los administradores de la Base de Datos:
![introduccion-cassandra-5.jpg]()
Luego tenemos la sección más importante dentro de nuestra interfaz web, y esta es Data, aquí podemos definir nuestros contenedores de información mejor conocidos como keyspaces y las “tablas” o column families.
Para crear un keyspace, primero debemos irnos a la sección Data y allí seleccionar la opción Add, ingresamos el nombre, la estrategia de replicación, la cual explicamos que puede ser simple o topología de red, y el factor de replicación.
Salvamos y ya tendríamos creado nuestro keyspace, como recordamos estos contenedores tienen una función clave en Cassandra y es definir el factor de replicación. Con nuestro contenedor definido vamos a agregar un column family, para ello ingresamos en el keyspace y seleccionamos la opción Add. Aquí ingresamos el nombre, el tipo de columna y el tipo de comparador.
Con esto ya hemos creado nuestra column family, como vemos es sumamente sencillo, sin embargo esta interfaz nos limita en muchas cosas y es solo un buen punto de partida para los usuarios novatos que desean entender como es la estructura de Cassandra y como maneja los clusters, nodos, keyspaces y column families.
Con esto finalizamos este tutorial, donde pudimos ver como es la arquitectura de Cassandra, su protocolo, componentes y la instalación de la misma. Conocimos la estructura mediante la interfaz web pero con esto solo hemos tocado la punta del iceberg, en próximos tutoriales entraremos de lleno con CQL y la forma de trabajar de manera profesional con Cassandra.
El almacenamiento en Cassandra está definido como llave/valor donde una llave puede mapear a uno o más valores. Es una Base de Datos orientada a registros por filas, donde cada fila está identificada por su llave y la particularidad de este sistema es que una fila puede ser almacenada en más de un nodo.
Arquitectura de Cassandra
Antes de pasar a la instalación de Cassandra en nuestro sistema, debemos conocer un poco la arquitectura de esta Base de Datos, de esta forma sabremos con que contamos y que podemos lograr.
Factor de replicación
Cuando hablamos de replicación de la información, uno de las primeras preguntas que nos hacemos es: ¿Cuántas copias necesitamos? Esto en Cassandra no es una pregunta sencilla de responder, pero lo que debemos tener en cuenta es que este factor nos indica el número de nodos que son almacenados en una misma fila.
Por ejemplo, un factor de replicación de 2 nos garantiza que habrás dos copias de la información de los nodos en el cluster. Escoger el valor dos para el factor de replicación está bien para cubrir fallas en un nodo en el ambiente de desarrollo y puede ser lo mínimo para ambientes de producción, ya que si un nodo cae el otro se encargará de manejar todas las peticiones, así que es algo que debemos pensar con detenimiento antes de implementarlo.
Keyspace
Cassandra nos permite agrupar la información en algo llamado keyspaces, donde podemos decir que estos keyspaces son contenedores para la información de la aplicación. Un cluster tiene un keyspace por aplicación, sin embargo Cassandra usa estos keyspaces para el manejo de la replicación.
Column family
Luego de definir nuestro keyspace, dentro del mismo tenemos algo llamado column family, estos son contenedores por igual, pero para una colección de filas. Cada fila es una colección ordenada de columnas y podemos hacer una analogía con respecto a las Bases de Datos relacionales, donde las column family son algo similar a las tablas.
Estrategia de replicación
En Cassandra existen dos estrategias para la replicación de información, una de ellas y la que ya abordamos es la estrategia simple o SimpleStrategy que se encarga de copiar la información al siguiente nodo hasta que se cumpla el factor de replicación definido. La segunda estrategia es llamada NetworkTopologyStrategy, donde es la mejor opción si deseamos distribuir la información a lo largo de múltiples centros de datos.
El protocolo Gossip
El protocolo usado por Cassandra para compartir la locación de los nodos y la información de estos en el cluster es llamado Gossip. Donde estos nodos están constantemente “murmurando” e intercambiando información con hasta 3 nodos en el cluster.
Este protocolo como otros tiene sus reglas para enviar peticiones a otros nodos, donde podemos ver tres pasos para el mismo, y cada nodo repite siempre estos pasos:
1- Murmurar a un nodo activo al azar.
2- Iniciar un murmuro hacia un nodo hacia abajo al azar.
3- Este paso es opcional y define que si el nodo seleccionado en el paso uno, no es un nodo semilla, murmurar a otro nodo semilla aleatorio.
Pero para mover la información y realizar la comunicación entre los nodos Cassandra usa un componente llamado Snitch, veamos a que se refiere.
Componente Snitch
Básicamente este componente se encarga de manejar el movimiento de la información entre nodos tomando otros nodos para consultas y replicación basadas en métricas varias. Esta configuración es la misma para todos los nodos dentro del cluster, sin embargo puede variar en su tipo, veamos cuales tenemos disponibles:
SimpleSnitch
Usado en despliegues simples de centros de datos, y un snitch configurado de esta forma no utiliza información alguna del centro de datos. Su comportamiento es simple, y es encontrar el siguiente nodo.
DynamicSnitching
Esta configuración monitorea el rendimiento de las réplicas y selecciona la mejor basada en una métrica simple que penaliza largos tiempos de respuesta y evita nodos que están comprimiendo su información.
RackInferringSnitch
Esta configuración lo que hace es usar la dirección IP para determinar la localización de los nodos, donde la última parte de la IP identifica el nodo, la segunda los racks y la tercera los centros de datos.
PropertyFileSnitch
Esta permite realizar la definición de la topología del cluster en un archivo de propiedades, por lo general se usa esta configuración si RackInferringSnitch no es aplicable.
GossipingPropertyFileSnitch
Utiliza un archivo de propiedades para la configuración inicial y continua con el murmuro para enviar información a otros nodos.
Instalando Cassandra
La instalación de Cassandra la realizaremos en un equipo con Windows 8, en el cual debemos cumplir con ciertos requerimientos antes, veamos que necesitamos:
1- Necesitamos tener al menos Java 7 instalado en nuestro sistema, sino lo tenemos podemos descargar la versión más reciente en el siguiente enlace.
2- Necesitamos adicionalmente Microsoft Visual C++ 2008 Redistributable Package (x86).
3- Por último conexión a Internet para poder descargar el paquete de DataStax.
Ya con nuestros requisitos revisados, vamos a irnos a la página del proyecto y buscaremos la versión de 32 o 64 bits que se adapte a nuestro sistema:
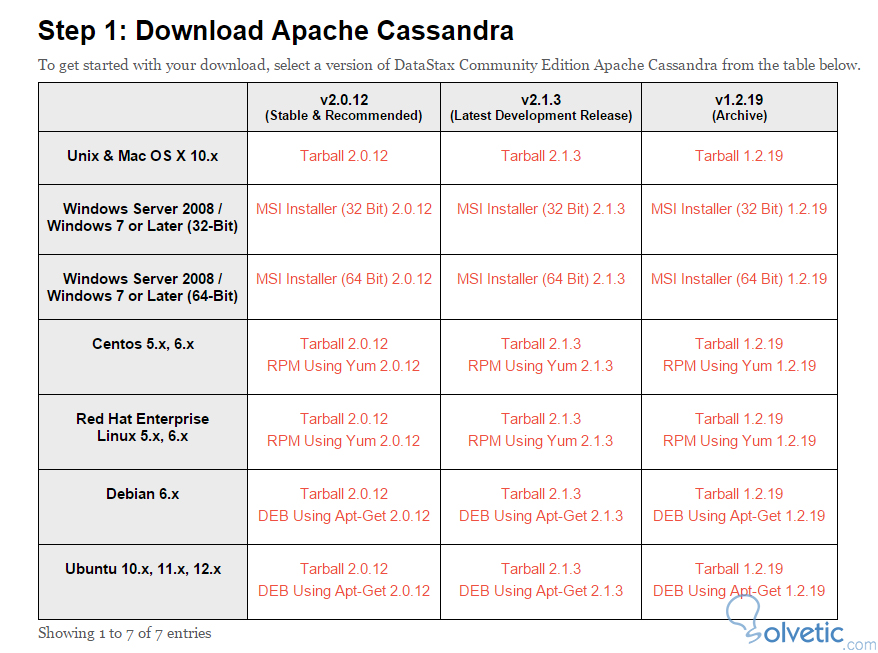
Si queremos darle un vistazo a la documentación de conectividad de Cassandra con los diferentes lenguajes de programación podemos bajar en la página y ver que necesitamos para lo mismo. Luego de la descarga, instalamos como cualquier aplicación de Windows. Donde es importante mencionar que luego de esta instalación, Cassandra nos creará por defecto un cluster de pruebas.
Interfaz web de DataStax
Con la instalación, varias herramientas son instaladas en nuestro sistema, una de ellas es la interfaz web de Cassandra llamada OpsCenter, a la cual podemos ingresar si colocamos en nuestro navegador la siguiente dirección:
http://localhost:8888/opscenter/index.htmlEsta interfaz nos permite realizar varias cosas interesantes, sin embargo no es lo más óptimo para trabajar con Cassandra, pero para efectos de este tutorial es importante conocerla, ver que nos ofrece y así tener un punto de partida para empezar a conocer la estructura de la Base de Datos.
Lo primero que nos encontramos al entrar en esta interfaz es la sección de Dashboard, donde podemos visualizar varias métricas de rendimientos como salud del nodo, capacidad de almacenamiento o peticiones de escritura:
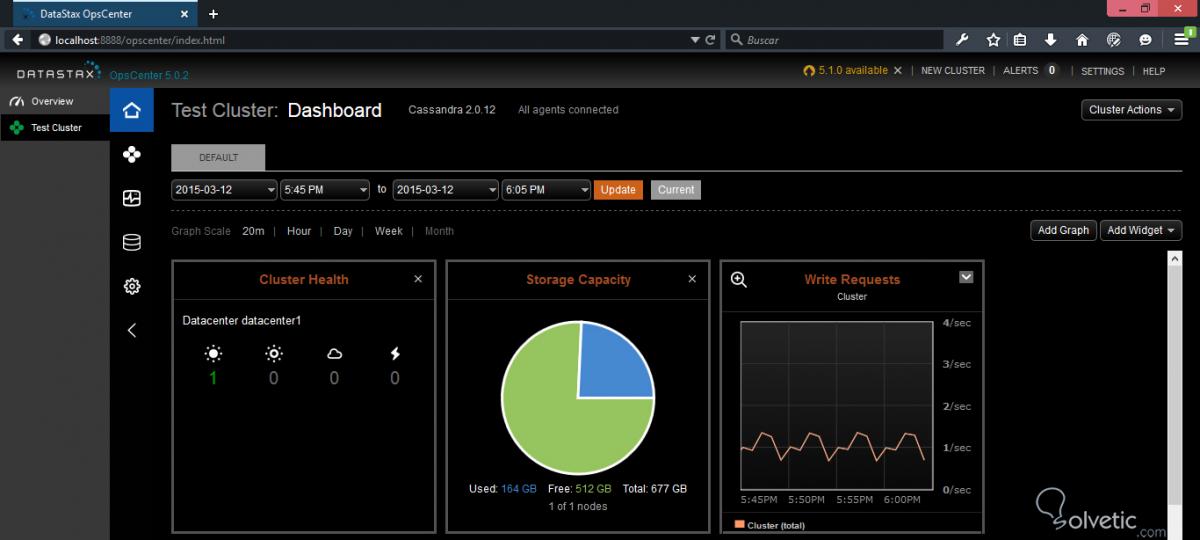
En esta interfaz podemos crear un nuevo cluster, para ello nos dirigimos a la parte superior derecha, y pulsamos New Cluster, lo cual nos abrirá la siguiente pantalla:
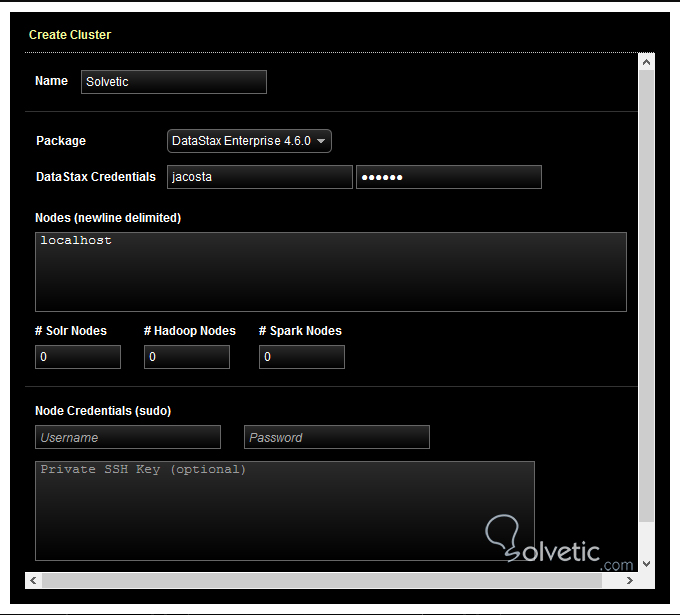
Ingresamos los datos solicitados y pulsamos en build cluster, adicionalmente a esto podremos añadir nodos por igual en el desplegable de Cluster Actions, en la parte superior derecha. En la sección Nodes, podemos ver los nodos disponibles y los centros de datos, así como ciertos parámetros como la salud, el tamaño de la data e inclusive las alertas generadas:
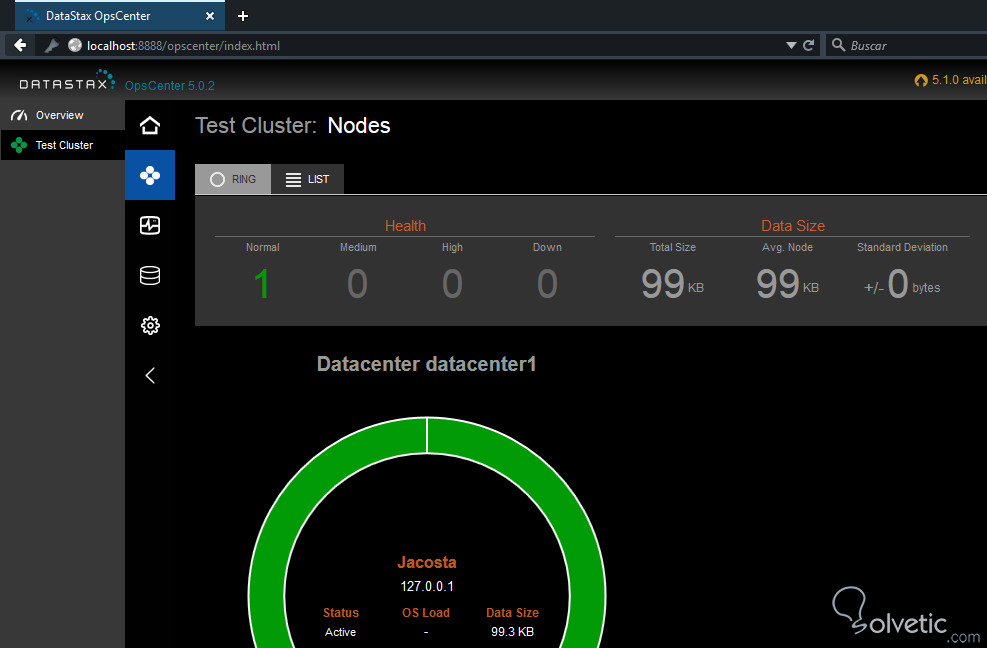
En la sección Activities podemos ver un listado de las actividades realizadas en el cluster, así como un log de eventos, algo bastante útil cuando somos los administradores de la Base de Datos:
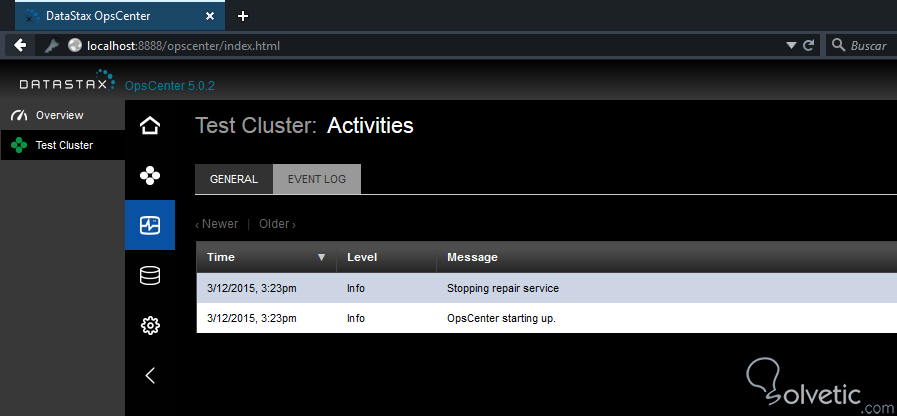
Luego tenemos la sección más importante dentro de nuestra interfaz web, y esta es Data, aquí podemos definir nuestros contenedores de información mejor conocidos como keyspaces y las “tablas” o column families.
Creando un keyspace y column families
Para crear un keyspace, primero debemos irnos a la sección Data y allí seleccionar la opción Add, ingresamos el nombre, la estrategia de replicación, la cual explicamos que puede ser simple o topología de red, y el factor de replicación.
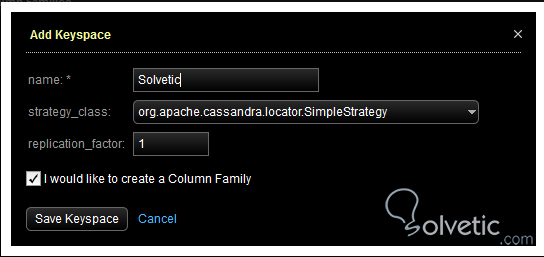
Salvamos y ya tendríamos creado nuestro keyspace, como recordamos estos contenedores tienen una función clave en Cassandra y es definir el factor de replicación. Con nuestro contenedor definido vamos a agregar un column family, para ello ingresamos en el keyspace y seleccionamos la opción Add. Aquí ingresamos el nombre, el tipo de columna y el tipo de comparador.
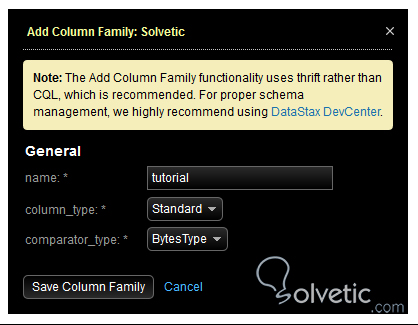
Con esto ya hemos creado nuestra column family, como vemos es sumamente sencillo, sin embargo esta interfaz nos limita en muchas cosas y es solo un buen punto de partida para los usuarios novatos que desean entender como es la estructura de Cassandra y como maneja los clusters, nodos, keyspaces y column families.
Con esto finalizamos este tutorial, donde pudimos ver como es la arquitectura de Cassandra, su protocolo, componentes y la instalación de la misma. Conocimos la estructura mediante la interfaz web pero con esto solo hemos tocado la punta del iceberg, en próximos tutoriales entraremos de lleno con CQL y la forma de trabajar de manera profesional con Cassandra.

