
Los sistemas operativos están basados en líneas de comandos que nos ofrecen múltiples opciones para aumentar las capacidades de la distribución al poder ejecutar búsquedas, acciones de administración, soporte y mucho más.
Justamente una de estas opciones está ligada a la posibilidad de buscar determinados tipos de archivos en Linux y así acceder fácilmente a su contenido y por ello hoy hablaremos de pdfgrep la cual está enfocada en la búsqueda de archivos PDF.
Qué es pdfgrep
Pdfgrep es una utilidad de línea de comandos para buscar texto en archivos PDF de forma simple y funcional ahorrándonos tiempo de acceder a cada archivo y buscar el texto con herramientas propias de PDF.
Algunas de sus características son:
Algunas de sus características son:
- Compatible con Grep, podremos ejecutar muchos parámetros de grep como -r, -i, -n o -c.
- Capacidad de buscar texto en múltiples archivos PDF
- Colores destacados, esta opción de color de GNU Grep es compatible y está habilitada por defecto.
- Admite el uso de expresiones regulares.
- Software libre
1. Instalar Pdfgrep en Linux
Paso 1
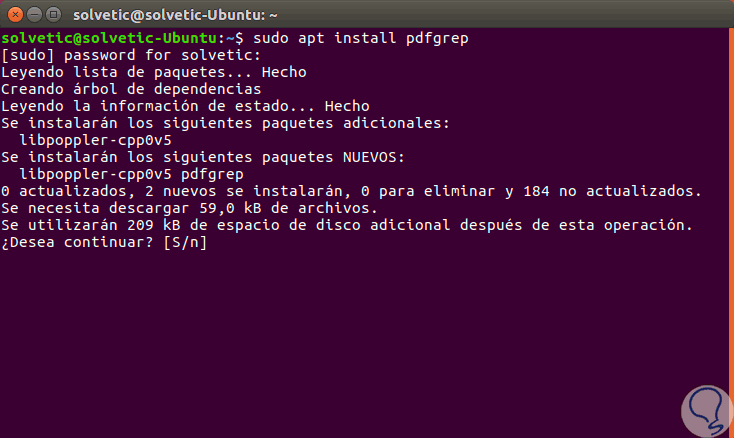
En este caso usaremos Ubuntu por lo cual basta con ejecutar la siguiente línea. Allí ingresamos la letra S para aceptar la descarga e instalación de los paquetes.
sudo apt install pdfgrep
Paso 2
Otras opciones de instalación son:
- Descargar el archivo .TAR.GZ en el siguiente enlace.
Paso 3
- O ejecutar el siguiente comando:
git clone https://gitlab.com/pdfgrep/pdfgrep.git
Paso 4
Posteriormente ingresar cada una de las siguientes líneas en su orden:
./configure make sudo make install
2. Usar Pdfgrep en Linux
Paso 1
Una vez instalado pdfgrep esta será la sintaxis a usar:
pdfgrep [OPCION...] PATTERN [ARCHIVO]
Paso 2
Cada uno de los elementos son:
- Opción: Indica los atributos que podemos añadir en la búsqueda, por ejemplo -i o --ignore-case, los cuales ignoran la distinción de letras mayúsculas y minúsculas entre el patrón que hemos indicado y el que debe coincidir con el archivo.
- Pattern: Indica una expresión regular extendida.
- Archivo: Es el archivo PDF donde se ha de ejecutar la búsqueda.
Paso 3
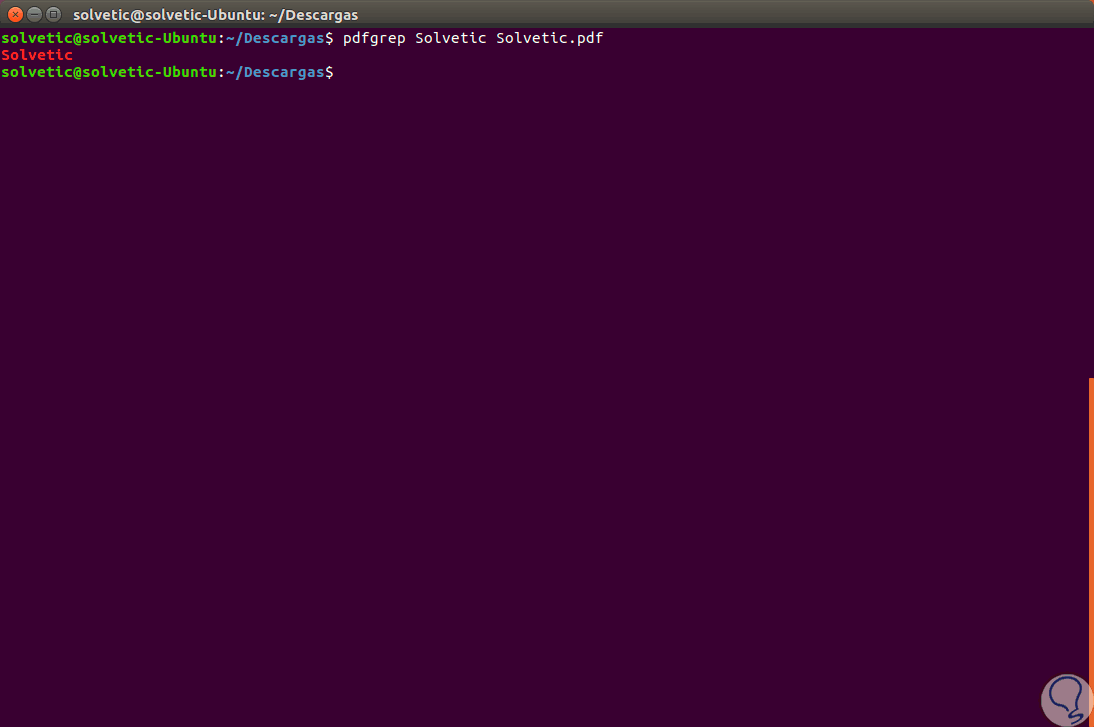
Iniciaremos con una búsqueda simple, por ejemplo, buscaremos la palabra Solvetic en el archivo Solvetic.pdf, para ello ejecutamos lo siguiente:
pdfgrep Solvetic Solvetic.pdf
Paso 4
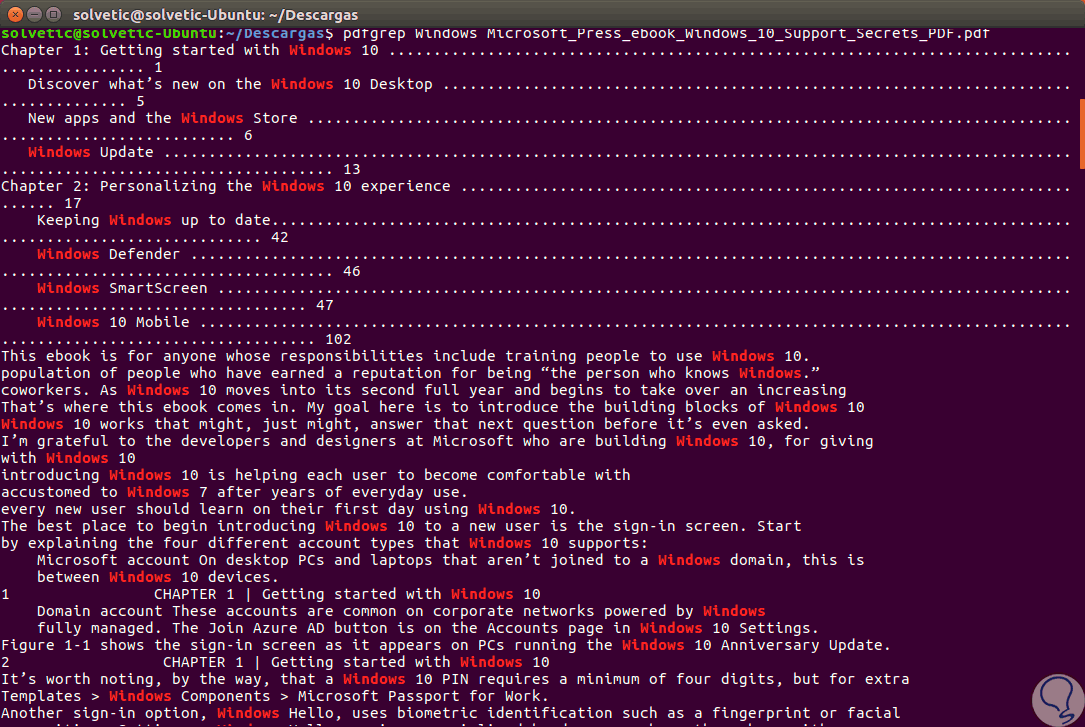
En este caso solo existe una vez este término en dicho archivo, pero, ahora buscaremos el término Windows en un archivo PDF oficial de Microsoft y este será el resultado que veremos:
Paso 5
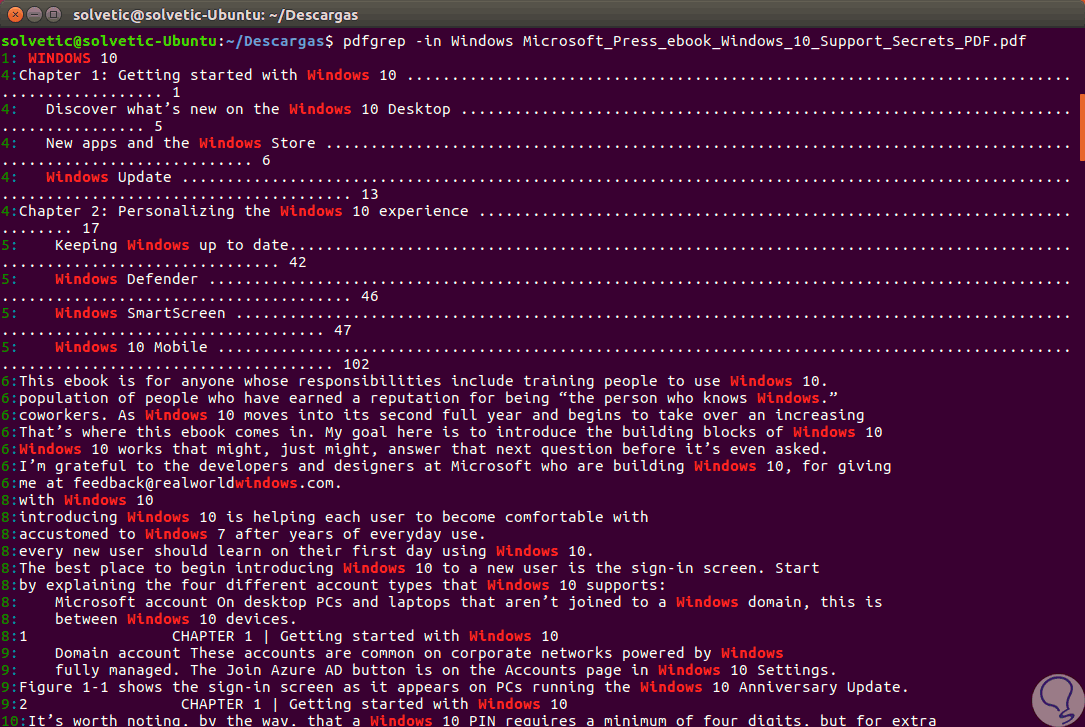
Podemos ver que la palabra buscada esta resaltada lo cual nos facilita su ubicación. Ahora, si añadimos el parámetro -in, será posible ver los resultados con el número de página donde se ha detectado dicho termino:
Paso 6
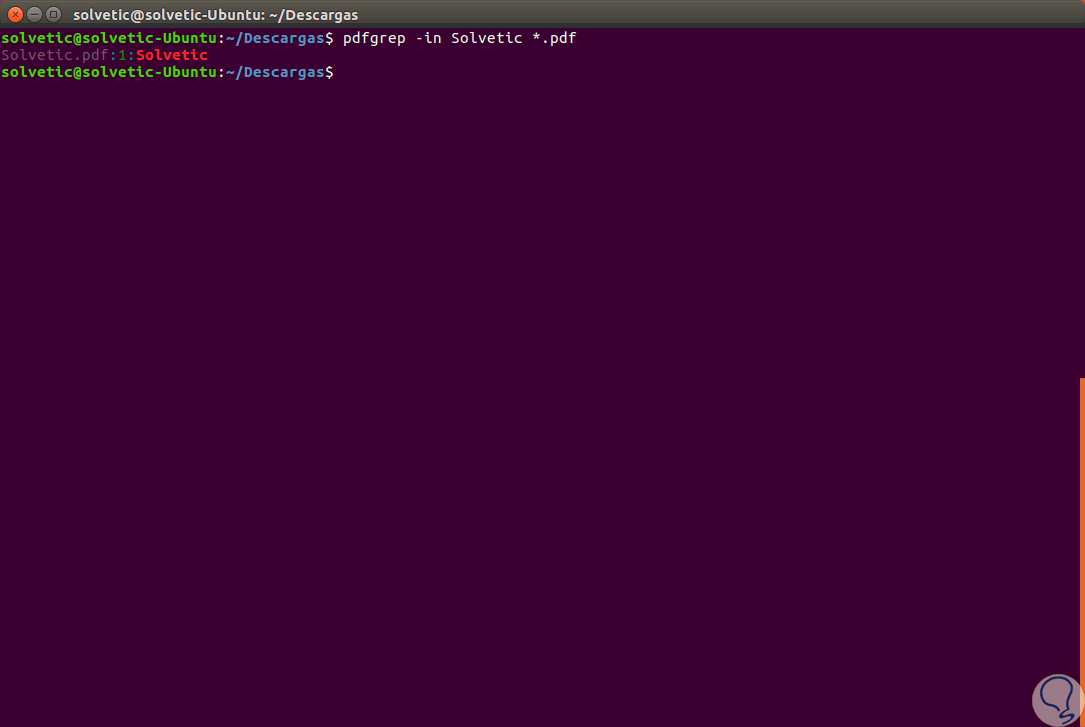
Otra de las opciones que podemos usar con pdfgrep es listar el o los archivos PDF que contengan un determinado término, para ello ejecutamos lo siguiente:
pdfgrep Solvetic *pdf
Paso 7
De esta forma será listado el archivo PDF donde se encuentra el término Solvetic:
Paso 8
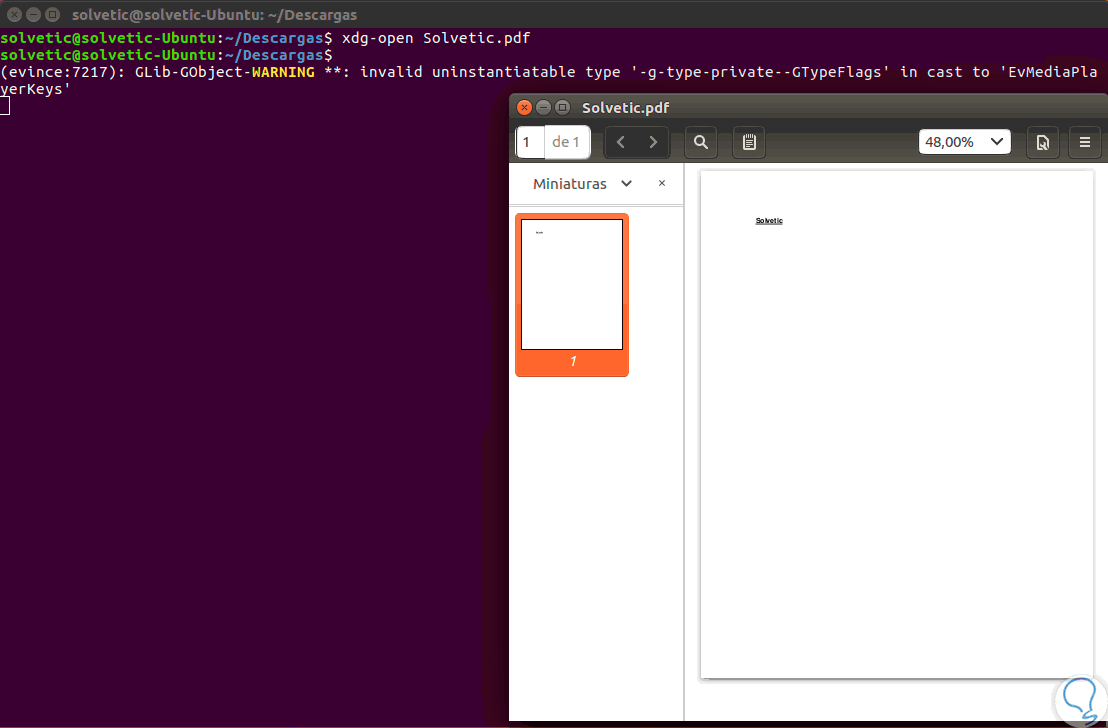
Si deseamos abrir el archivo PDF podemos ejecutar el siguiente comando:
xdg-open (Archivo.PDF)
Paso 9
Las opciones generales que nos ofrece pdfgrep son:
-i, --ignore-case
Ignora las distinciones de los casos tanto en el origen como en los archivos de entrada.
-F, --fixed-strings
Interpreta PATTERN como una lista de cadenas fijas separadas por líneas nuevas.
--cache
Usa una caché para el texto renderizado con el fin de acelerar la operación en archivos de gran tamaño.
-P, --perl-regexp
Interpreta PATTERN como una expresión regular compatible con Perl (PCRE).
-H, --with-filename
Imprime el nombre del archivo para cada coincidencia.
-h, --no-nombre de archivo
Suprime el prefijo del nombre de archivo en la salida.
-n, --page-number
Prefija cada coincidencia con el número de la página donde se encontró el termino buscado.
-c, --count
Suprime la salida normal y, en su lugar, imprime el número de coincidencias para cada archivo de entrada.
-p, --Conteo de páginas
Imprime el número de coincidencias por página. Implica -n.
--color
Permite resaltar nombres de archivos, números de página y texto coincidente con diferentes secuencias para mostrarlos en color en la terminal, algunas de sus opciones son Siempre, nuca o automático.
-o, --only-matching
Imprime solo la parte coincidente de una línea sin ningún contexto circundante.
-r, --recursive
Nos permite buscar de forma recursiva todos los archivos (restringidos por --include y --exclude) debajo de cada directorio, siguiendo los enlaces simbólicos solo si están en la línea de comando.
-R, --de referencia-recursiva
Igual que -r, pero sigue todos los enlaces simbólicos.
-quiet o -q
Nos permite salir de la aplicación.
Con esto pdfgrep se convierte en una solución ideal a la hora de trabajar con archivos PDF en ambientes Linux.

Si eres de Linux y quieres editar documentos PDF, aquí vas a encontrar los mejores programas gratuitos para ello. ¿Quieres conocerlos? Allá vamos!

