En tutoriales pasados hemos estado enfocados en la estructura y por ende la creación de las tablas en Cassandra, vimos a profundidad como trabajar con los tipos de datos, definir las propiedades de las tablas e incluso indicarle al motor como debe ser la organización de nuestra información.
Ya con estos conocimientos podemos pasar a aspectos más complejos y que hacen un todo en el mundo de Base de Datos, esto es la manipulación de la información en nuestro entorno, veamos que podemos lograr con Cassandra.
La inserción de la información en cualquier Base de Datos es una de las operaciones principales y que a partir de la misma se derivan las demás. En Cassandra es bastante sencillo y posee un cierto parecido con la sintaxis SQL tradicional, se utiliza la palabra INSERT INTO seguido del nombre de la tabla seguido de las columnas y utilizando VALUES se especifica la información a ser insertada.
Vamos a utilizar las tablas utilizadas en tutoriales pasados, sin embargo se deja a continuación el CQL de algunas de estas tablas para los usuarios que no las posean en su entorno:
CREATE TABLE usuarios ( usuario text, password text, nombre text, apellido text, pais text, PRIMARY KEY (usuario) ); CREATE TABLE tutorial ( usuario text, fecha timestamp, titulo text, categoria text, contenido text, PRIMARY KEY (usuario, fecha) );Ya con las tablas creadas vamos a realizar la primera inserción en la tabla de usuarios, aquí es bastante sencillo ya que todas las columnas son de tipo text, veamos entonces cómo queda nuestra sentencia CQL:
INSERT INTO
usuarios (usuario, password, nombre, apellido, pais)
VALUES ('jacosta', '123456', 'Jon', 'Acosta', 'Spain');Siendo todos los valores de tipo de texto solo tuvimos que especificarlos con comillas simples, veamos que la inserción se realizó con éxito ejecutando un SELECT a nuestra tabla:
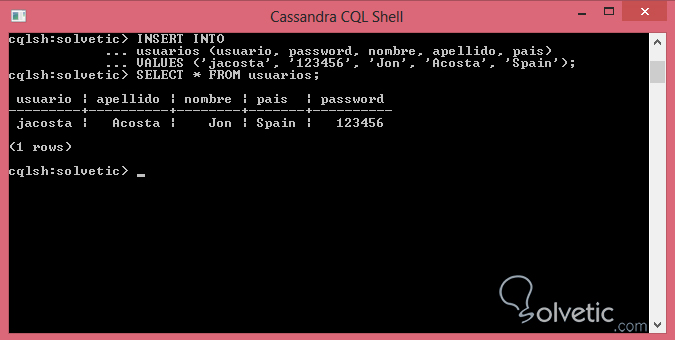
Como pudimos ver la inserción fue realizada con éxito y si comparamos la operación con su par en SQL, fue mucho más sencilla de ejecutar, vamos a realizar otra inserción de datos pero esta vez en nuestra tabla tutorial, donde poseemos un campo de tipo timestamp:
INSERT INTO
tutorial (usuario, fecha, titulo, categoria, contenido)
VALUES ('jacosta', '2015-04-12 11:35:20', ‘Manipulacion data Cassandra’, 'Bases de Datos', 'Contenido del tutorial');Como pudimos apreciar para la inserción de un dato de tipo timestamp con solo seguir la estructura adecuada pudimos hacerlo sin ningún problema, realizamos una consulta a nuestra tabla la cual debe verse de la siguiente forma:
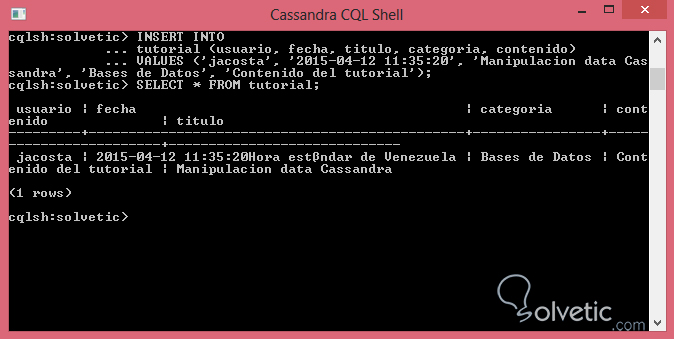
En ocasiones como es de esperarse en cualquier desarrollo, la información en nuestra Base de Datos puede ser modificada, para ello contamos con UPDATE para la actualización de los registros, sin embargo Cassandra funciona de manera diferente a como estamos acostumbrados en el modelo relacional, veamos la sintaxis primero:
UPDATE tutorial SET titulo = 'Titulo modificado' WHERE usuario = 'jacosta' AND fecha='2015-04-13 11:35:20';Pudimos actualizar sin ningún problema, sin embargo el proceso de actualizar en Cassandra lo que hace es añadir una nueva columna dentro de la fila con el timestamp más reciente y marca las columnas viejas con una especie de marcadores, estos marcadores no se hacen efectivo de manera inmediata pero al realizar una consulta Cassandra verifica las dos columnas y quien tenga el timestamp más reciente gana, veamos:
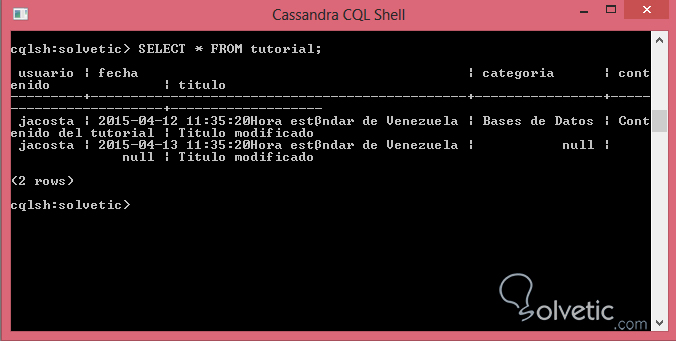
Cassandra también difiere en términos de inserción de data con respecto a Bases de Datos SQL tradicionales, por ejemplo si tratamos de inserta los mismos valores con el usuario jacosta el cual es la llave primaria obtendríamos un error, sin embargo Cassandra es diferente y su misión es insertar columnas. La particularidad de esto es que así como mencionamos en la actualización de la información, Cassandra retornará la fila que sea más nueva por así decirlo, vamos a insertar una data con el mismo usuario, variando el resto de la información:
INSERT INTO
tutorial (usuario, fecha, titulo, categoria, contenido)
VALUES ('jacosta', '2015-04-22 06:35:20', ‘Mismo usuario’, 'BD', 'Contenido nuevo');Si consultamos nuestra tabla vemos que están todos los registros en la misma sin importar que repitan la misma llave primary como vemos en la siguiente imagen, en la cual además podemos verificar que no se generó ningún error al realizar el INSERT:
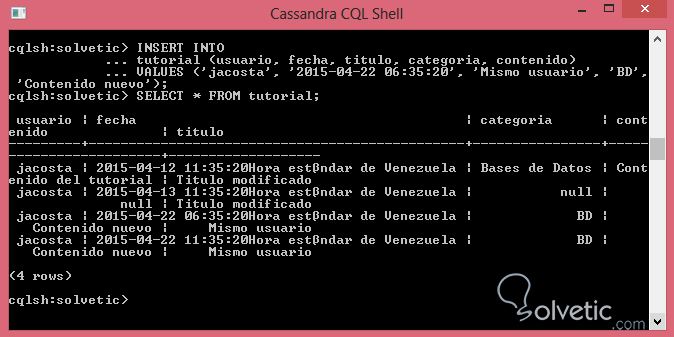
Para eliminar la información Cassandra funciona de manera distinta a la sintaxis SQL usual, donde no hay necesidad de especificar con la cláusula WHERE para eliminar la información, lo cual al ejecutarse elimina todas los registros en la tabla, esto es bastante peligroso ya que podemos perder nuestra información debido al mal uso de la sentencia.
Cassandra hace obligatorio el uso de la cláusula WHERE así blindando nuestra información, vamos entonces a eliminar los registros que cumplan con el usuario jacosta:
DELETE FROM tutorial WHERE usuario = 'jacosta';Esto eliminará todos los tutorial subidos por el usuario especificado, esto no está mal pero todavía dista de ser lo más óptimo, para ello vamos a utilizar el resto de las llaves especificadas, en este caso la clustering key fecha, veamos cómo queda nuestra sentencia CQL:
DELETE FROM tutorial WHERE usuario = 'jacosta' AND fecha = '2015-04-22 06:35:20';Veamos entonces en la siguiente imagen como tenemos disponibles dos registros con el mismo usuario o llave primaria, y con nuestro DELETE más específico pudimos eliminar el registro que deseamos:
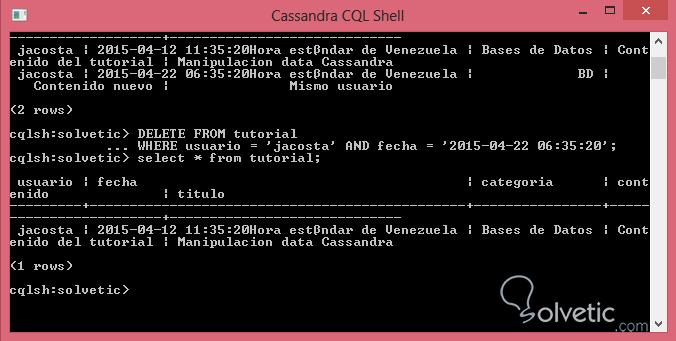
Hasta el momento hemos podido ver varios tipos de manipulación de la información, pero todas estas bastante sencillas de implementar y adicionalmente hemos utilizado el SELECT para consultar los cambios hechos por estas operaciones, pero esta cláusula tiene mucho más de lo que está a la vista, donde a pesar que su sintaxis es similar a SQL su comportamiento puede variar.
Una de estas variaciones o diferencias que posee el SELECT del lenguaje CQL con respecto al SQL son las siguientes:
La construcción de los queries anteriormente había sido bastante sencillo ya que sabíamos el nombre de los keyspaces, tablas y columnas, pero ¿Qué pasa si no sabemos los nombres para hacer nuestros queries? En estos casos contamos con el comando DESCRIBE, vamos a ejecutarlo para identificar primeramente los keyspaces:
DESCRIBE keyspaces;Veamos como luce la ejecución del comando:
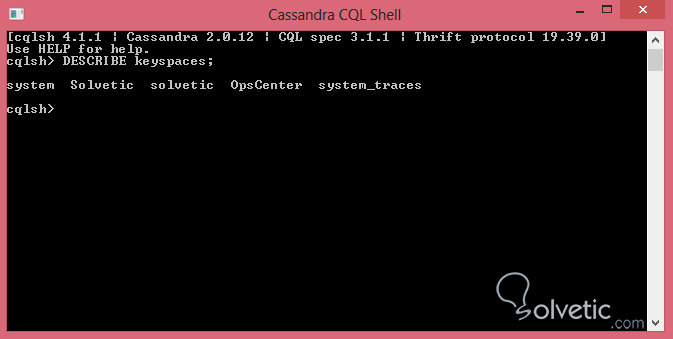
Como vemos es bastante útil y nos permite obtener todos los keyspaces presentes en nuestra cluster. Adicionalmente podemos utilizar DESCRIBE para ver las tablas disponibles en los keyspaces, veamos como luce esto:
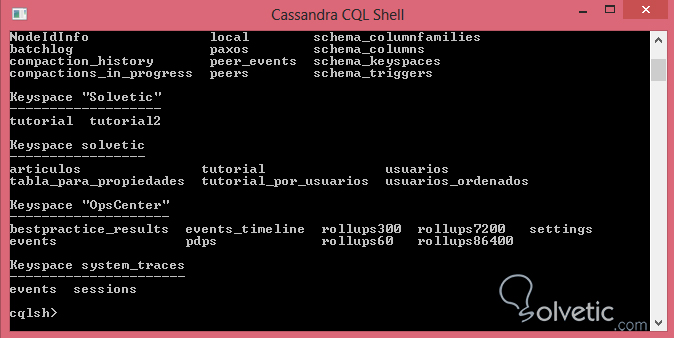
Como podemos visualizar Cassandra nos da una lista de los keyspaces y las tablas contenidas en una cada de ellos, sin embargo el comando DESCRIBE va un paso más allá y podemos bajar un nivel más en la estructura, ya que lo que más nos interesa son las columnas de alguna tabla en específico, veamos el resultado arrojado por la consola de comandos:
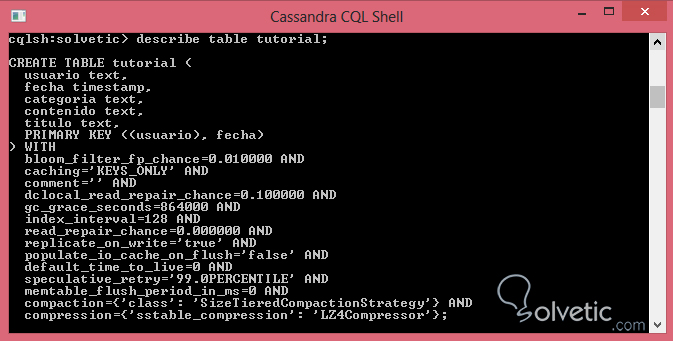
Como pudimos ver el comando DESCRIBE es bastante poderoso, ya que no solo nos retorna el nombre de las columnas de nuestra tabla, sino que nos retorna el tipo de dato para cada una de las columnas e incluso las propiedades como comentarios, compresión y compactación por mencionar algunas.
Ya sabiendo que tiene nuestra tabla, podemos entonces aplicar de manera efectiva nuestro comando SELECT, donde podemos seleccionar solo las columnas que necesitemos:
SELECT usuario, fecha, titulo FROM tutorial;O simplemente filtrar por un usuario en específico:
SELECT usuario, fecha, titulo FROM tutorial WHERE usuario = 'jacosta';Incluso podemos filtrar por múltiples usuarios, si venimos del mundo SQL podemos aplicar el operador OR, sin embargo este no existe en Cassandra, para ello debemos usar IN, veamos:
SELECT usuario, fecha, titulo
FROM tutorial WHERE usuario IN ('jacosta', 'cperez');Por ultimo podemos realizar el filtro de nuestra información por rangos, en este caso podemos aplicar un filtro por rango de fechas. Para ello con solo aplicar los operadores mayor que y menor que, junto a AND lo podemos lograr. veamos cómo nos quedaría:SELECT usuario, fecha, titulo FROM tutorial WHERE usuario = ‘jacosta’ AND fecha > '2015-04-12' AND fecha < '2015-04-26';Con esto último finalizamos este tutorial donde pudimos ver como Cassandra no solo es ponderosa sino sumamente sencilla de manejar dándonos una sintaxis similar a la que estamos acostumbrados si venimos del mundo SQL para realizar las operaciones necesarias para la manipulación de la información dentro de nuestras tablas.

